Semantics-aware human motion generation from audio instructions
IF 2.2
4区 计算机科学
Q2 COMPUTER SCIENCE, SOFTWARE ENGINEERING
引用次数: 0
Abstract
Recent advances in interactive technologies have highlighted the prominence of audio signals for semantic encoding. This paper explores a new task, where audio signals are used as conditioning inputs to generate motions that align with the semantics of the audio. Unlike text-based interactions, audio provides a more natural and intuitive communication method. However, existing methods typically focus on matching motions with music or speech rhythms, which often results in a weak connection between the semantics of the audio and generated motions. We propose an end-to-end framework using a masked generative transformer, enhanced by a memory-retrieval attention module to handle sparse and lengthy audio inputs. Additionally, we enrich existing datasets by converting descriptions into conversational style and generating corresponding audio with varied speaker identities. Experiments demonstrate the effectiveness and efficiency of the proposed framework, demonstrating that audio instructions can convey semantics similar to text while providing more practical and user-friendly interactions.
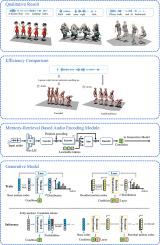
从音频指令生成语义感知的人体运动
交互技术的最新进展突出了音频信号在语义编码中的重要性。本文探索了一个新的任务,其中音频信号被用作条件反射输入,以产生与音频语义一致的运动。与基于文本的交互不同,音频提供了一种更自然、更直观的交流方式。然而,现有的方法通常侧重于将动作与音乐或语音节奏相匹配,这往往导致音频的语义与生成的动作之间的联系很弱。我们提出了一个端到端框架,使用屏蔽生成转换器,增强了一个记忆检索注意力模块来处理稀疏和冗长的音频输入。此外,我们通过将描述转换为会话风格并生成具有不同说话者身份的相应音频来丰富现有数据集。实验证明了该框架的有效性和效率,表明音频指令可以传达与文本相似的语义,同时提供更实用和用户友好的交互。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Graphical Models
工程技术-计算机:软件工程
CiteScore
3.60
自引率
5.90%
发文量
15
审稿时长
47 days
期刊介绍:
Graphical Models is recognized internationally as a highly rated, top tier journal and is focused on the creation, geometric processing, animation, and visualization of graphical models and on their applications in engineering, science, culture, and entertainment. GMOD provides its readers with thoroughly reviewed and carefully selected papers that disseminate exciting innovations, that teach rigorous theoretical foundations, that propose robust and efficient solutions, or that describe ambitious systems or applications in a variety of topics.
We invite papers in five categories: research (contributions of novel theoretical or practical approaches or solutions), survey (opinionated views of the state-of-the-art and challenges in a specific topic), system (the architecture and implementation details of an innovative architecture for a complete system that supports model/animation design, acquisition, analysis, visualization?), application (description of a novel application of know techniques and evaluation of its impact), or lecture (an elegant and inspiring perspective on previously published results that clarifies them and teaches them in a new way).
GMOD offers its authors an accelerated review, feedback from experts in the field, immediate online publication of accepted papers, no restriction on color and length (when justified by the content) in the online version, and a broad promotion of published papers. A prestigious group of editors selected from among the premier international researchers in their fields oversees the review process.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


