Jordan Eskenazi, Varun Krishnan, Maximilian Konarzewski, David Constantinescu, Gilberto Lobaton, Seth D Dodds
{"title":"Evaluating retrieval augmented generation and ChatGPT's accuracy on orthopaedic examination assessment questions.","authors":"Jordan Eskenazi, Varun Krishnan, Maximilian Konarzewski, David Constantinescu, Gilberto Lobaton, Seth D Dodds","doi":"10.21037/aoj-24-49","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Since the introduction of large language models (LLMs) such as ChatGPT, there has been a race to test its capability in medical problem solving across specialties to varying degrees of success. Retrieval augmented generation (RAG) allows LLMs to leverage subject specific knowledge to provide context, a greater number of sources, and the ability to cite medical literature to increase the accuracy and credibility of its answers. The use of LLM + RAG has not yet been used in the appraisal of artificial intelligence's capability of orthopedic problem solving. The purpose of this study is to assess the performance of ChatGPT + RAG against the performance of ChatGPT without RAG as well as against humans on orthopedic examination assessment questions.</p><p><strong>Methods: </strong>The American Academy of Orthopaedic Surgeons (AAOS) OrthoWizard question bank was used as the source of questions. After 13 textbooks and 28 clinical guidelines were made available for RAG, text-only multiple-choice questions were presented in a zero-shot learning fashion to ChatGPT-4 + RAG, ChatGPT-4, and ChatGPT-3.5.</p><p><strong>Results: </strong>On 1,023 questions tested, ChatGPT-3.5, ChatGPT-4, ChatGPT-4+RAG, and humans scored 52.98%, 64.91%, 73.80%, and 73.97%, respectively. There was no statistical difference between orthopedic surgeons and ChatGPT-4 + RAG on overall accuracy (P>0.99). Both orthopedic surgeons and ChatGPT4 + RAG scored better than ChatGPT-4 (P<0.001) and ChatGPT-3.5 (P<0.001). Of the 13 textbooks available to RAG, RAG used AAOS Comprehensive Review 3 Volume 3 for 39.6% of questions, more often than any other resource available to it.</p><p><strong>Conclusions: </strong>ChatGPT-4 + RAG was able to answer 1,023 questions from the OrthoWizard question bank at the same accuracy as Orthopedic surgeons. Both ChatGPT-4 + RAG and orthopedic surgeons had superior accuracy on these specialty exam questions compared to ChatGPT-4 and ChatGPT-3.5. Artificial intelligence is becoming increasingly accurate in its ability to answer orthopaedic surgery test questions with the guidance of orthopaedic surgery textbooks. RAG enables an LLM to effectively cite its sources after providing an answer to a question, which is an important tool for the integration of LLMs to orthopaedic surgery education and can function as a valuable tool for anyone studying for an orthopedic examination.</p>","PeriodicalId":44459,"journal":{"name":"Annals of Joint","volume":"10 ","pages":"12"},"PeriodicalIF":0.9000,"publicationDate":"2025-04-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12082174/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Annals of Joint","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.21037/aoj-24-49","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q4","JCRName":"ORTHOPEDICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Since the introduction of large language models (LLMs) such as ChatGPT, there has been a race to test its capability in medical problem solving across specialties to varying degrees of success. Retrieval augmented generation (RAG) allows LLMs to leverage subject specific knowledge to provide context, a greater number of sources, and the ability to cite medical literature to increase the accuracy and credibility of its answers. The use of LLM + RAG has not yet been used in the appraisal of artificial intelligence's capability of orthopedic problem solving. The purpose of this study is to assess the performance of ChatGPT + RAG against the performance of ChatGPT without RAG as well as against humans on orthopedic examination assessment questions.
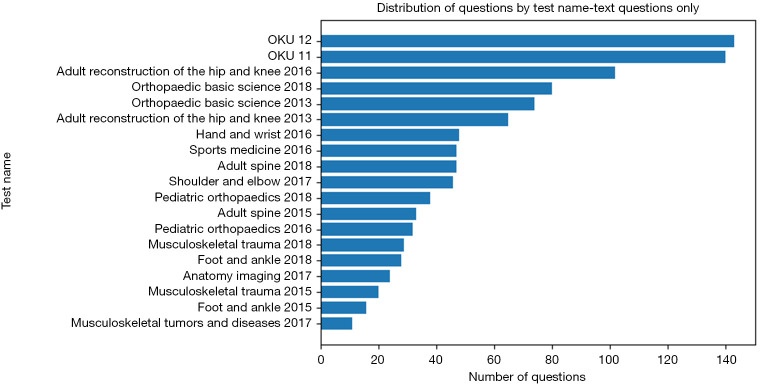
Methods: The American Academy of Orthopaedic Surgeons (AAOS) OrthoWizard question bank was used as the source of questions. After 13 textbooks and 28 clinical guidelines were made available for RAG, text-only multiple-choice questions were presented in a zero-shot learning fashion to ChatGPT-4 + RAG, ChatGPT-4, and ChatGPT-3.5.
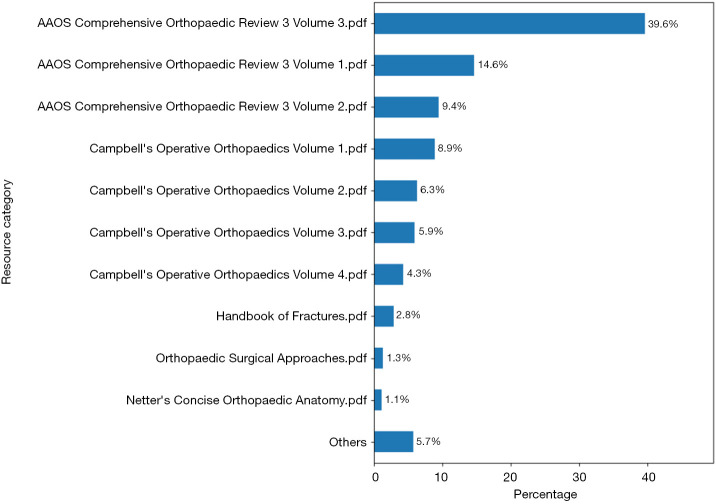
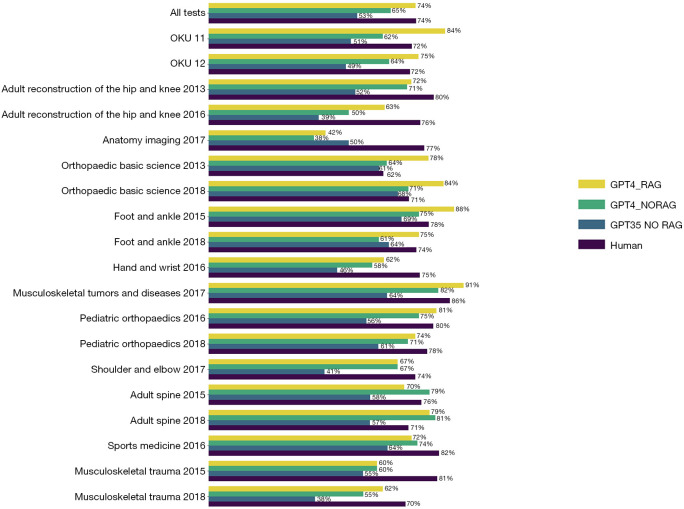
Results: On 1,023 questions tested, ChatGPT-3.5, ChatGPT-4, ChatGPT-4+RAG, and humans scored 52.98%, 64.91%, 73.80%, and 73.97%, respectively. There was no statistical difference between orthopedic surgeons and ChatGPT-4 + RAG on overall accuracy (P>0.99). Both orthopedic surgeons and ChatGPT4 + RAG scored better than ChatGPT-4 (P<0.001) and ChatGPT-3.5 (P<0.001). Of the 13 textbooks available to RAG, RAG used AAOS Comprehensive Review 3 Volume 3 for 39.6% of questions, more often than any other resource available to it.
Conclusions: ChatGPT-4 + RAG was able to answer 1,023 questions from the OrthoWizard question bank at the same accuracy as Orthopedic surgeons. Both ChatGPT-4 + RAG and orthopedic surgeons had superior accuracy on these specialty exam questions compared to ChatGPT-4 and ChatGPT-3.5. Artificial intelligence is becoming increasingly accurate in its ability to answer orthopaedic surgery test questions with the guidance of orthopaedic surgery textbooks. RAG enables an LLM to effectively cite its sources after providing an answer to a question, which is an important tool for the integration of LLMs to orthopaedic surgery education and can function as a valuable tool for anyone studying for an orthopedic examination.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


