{"title":"Large Language Models in Biochemistry Education: Comparative Evaluation of Performance.","authors":"Olena Bolgova, Inna Shypilova, Volodymyr Mavrych","doi":"10.2196/67244","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Recent advancements in artificial intelligence (AI), particularly in large language models (LLMs), have started a new era of innovation across various fields, with medicine at the forefront of this technological revolution. Many studies indicated that at the current level of development, LLMs can pass different board exams. However, the ability to answer specific subject-related questions requires validation.</p><p><strong>Objective: </strong>The objective of this study was to conduct a comprehensive analysis comparing the performance of advanced LLM chatbots-Claude (Anthropic), GPT-4 (OpenAI), Gemini (Google), and Copilot (Microsoft)-against the academic results of medical students in the medical biochemistry course.</p><p><strong>Methods: </strong>We used 200 USMLE (United States Medical Licensing Examination)-style multiple-choice questions (MCQs) selected from the course exam database. They encompassed various complexity levels and were distributed across 23 distinctive topics. The questions with tables and images were not included in the study. The results of 5 successive attempts by Claude 3.5 Sonnet, GPT-4-1106, Gemini 1.5 Flash, and Copilot to answer this questionnaire set were evaluated based on accuracy in August 2024. Statistica 13.5.0.17 (TIBCO Software Inc) was used to analyze the data's basic statistics. Considering the binary nature of the data, the chi-square test was used to compare results among the different chatbots, with a statistical significance level of P<.05.</p><p><strong>Results: </strong>On average, the selected chatbots correctly answered 81.1% (SD 12.8%) of the questions, surpassing the students' performance by 8.3% (P=.02). In this study, Claude showed the best performance in biochemistry MCQs, correctly answering 92.5% (185/200) of questions, followed by GPT-4 (170/200, 85%), Gemini (157/200, 78.5%), and Copilot (128/200, 64%). The chatbots demonstrated the best results in the following 4 topics: eicosanoids (mean 100%, SD 0%), bioenergetics and electron transport chain (mean 96.4%, SD 7.2%), hexose monophosphate pathway (mean 91.7%, SD 16.7%), and ketone bodies (mean 93.8%, SD 12.5%). The Pearson chi-square test indicated a statistically significant association between the answers of all 4 chatbots (P<.001 to P<.04).</p><p><strong>Conclusions: </strong>Our study suggests that different AI models may have unique strengths in specific medical fields, which could be leveraged for targeted support in biochemistry courses. This performance highlights the potential of AI in medical education and assessment.</p>","PeriodicalId":36236,"journal":{"name":"JMIR Medical Education","volume":"11 ","pages":"e67244"},"PeriodicalIF":3.2000,"publicationDate":"2025-04-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12005600/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Education","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/67244","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"EDUCATION, SCIENTIFIC DISCIPLINES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Recent advancements in artificial intelligence (AI), particularly in large language models (LLMs), have started a new era of innovation across various fields, with medicine at the forefront of this technological revolution. Many studies indicated that at the current level of development, LLMs can pass different board exams. However, the ability to answer specific subject-related questions requires validation.
Objective: The objective of this study was to conduct a comprehensive analysis comparing the performance of advanced LLM chatbots-Claude (Anthropic), GPT-4 (OpenAI), Gemini (Google), and Copilot (Microsoft)-against the academic results of medical students in the medical biochemistry course.
Methods: We used 200 USMLE (United States Medical Licensing Examination)-style multiple-choice questions (MCQs) selected from the course exam database. They encompassed various complexity levels and were distributed across 23 distinctive topics. The questions with tables and images were not included in the study. The results of 5 successive attempts by Claude 3.5 Sonnet, GPT-4-1106, Gemini 1.5 Flash, and Copilot to answer this questionnaire set were evaluated based on accuracy in August 2024. Statistica 13.5.0.17 (TIBCO Software Inc) was used to analyze the data's basic statistics. Considering the binary nature of the data, the chi-square test was used to compare results among the different chatbots, with a statistical significance level of P<.05.
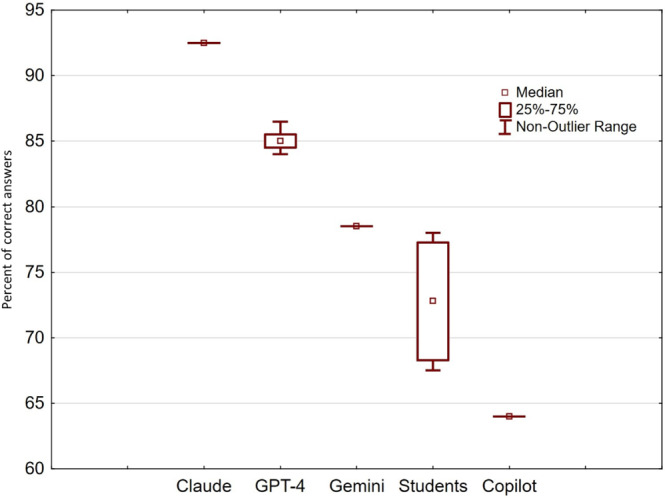
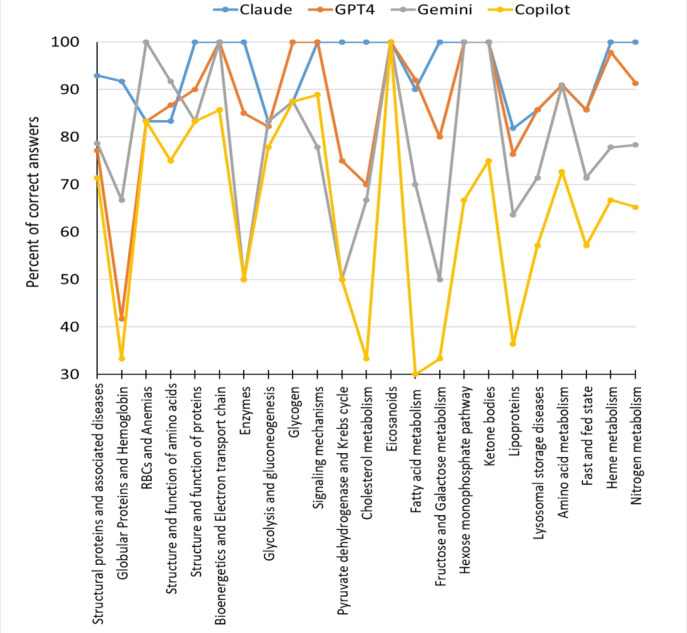
Results: On average, the selected chatbots correctly answered 81.1% (SD 12.8%) of the questions, surpassing the students' performance by 8.3% (P=.02). In this study, Claude showed the best performance in biochemistry MCQs, correctly answering 92.5% (185/200) of questions, followed by GPT-4 (170/200, 85%), Gemini (157/200, 78.5%), and Copilot (128/200, 64%). The chatbots demonstrated the best results in the following 4 topics: eicosanoids (mean 100%, SD 0%), bioenergetics and electron transport chain (mean 96.4%, SD 7.2%), hexose monophosphate pathway (mean 91.7%, SD 16.7%), and ketone bodies (mean 93.8%, SD 12.5%). The Pearson chi-square test indicated a statistically significant association between the answers of all 4 chatbots (P<.001 to P<.04).
Conclusions: Our study suggests that different AI models may have unique strengths in specific medical fields, which could be leveraged for targeted support in biochemistry courses. This performance highlights the potential of AI in medical education and assessment.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


