{"title":"Coherent Interpretation of Entire Visual Field Test Reports Using a Multimodal Large Language Model (ChatGPT).","authors":"Jeremy C K Tan","doi":"10.3390/vision9020033","DOIUrl":null,"url":null,"abstract":"<p><p>This study assesses the accuracy and consistency of a commercially available large language model (LLM) in extracting and interpreting sensitivity and reliability data from entire visual field (VF) test reports for the evaluation of glaucomatous defects. Single-page anonymised VF test reports from 60 eyes of 60 subjects were analysed by an LLM (ChatGPT 4o) across four domains-test reliability, defect type, defect severity and overall diagnosis. The main outcome measures were accuracy of data extraction, interpretation of glaucomatous field defects and diagnostic classification. The LLM displayed 100% accuracy in the extraction of global sensitivity and reliability metrics and in classifying test reliability. It also demonstrated high accuracy (96.7%) in diagnosing whether the VF defect was consistent with a healthy, suspect or glaucomatous eye. The accuracy in correctly defining the type of defect was moderate (73.3%), which only partially improved when provided with a more defined region of interest. The causes of incorrect defect type were mostly attributed to the wrong location, particularly confusing the superior and inferior hemifields. Numerical/text-based data extraction and interpretation was overall notably superior to image-based interpretation of VF defects. This study demonstrates the potential and also limitations of multimodal LLMs in processing multimodal medical investigation data such as VF reports.</p>","PeriodicalId":36586,"journal":{"name":"Vision (Switzerland)","volume":"9 2","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2025-04-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12015771/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Vision (Switzerland)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/vision9020033","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Medicine","Score":null,"Total":0}
引用次数: 0
Abstract
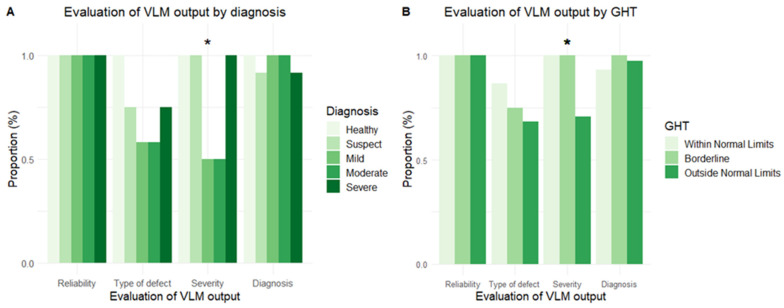
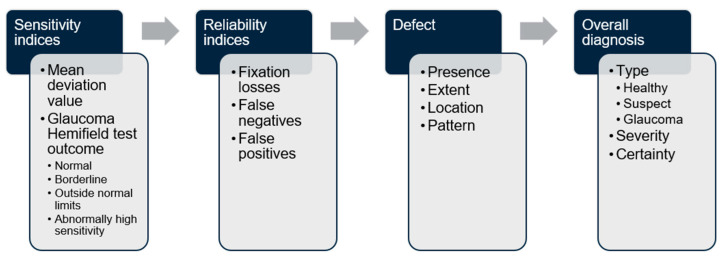
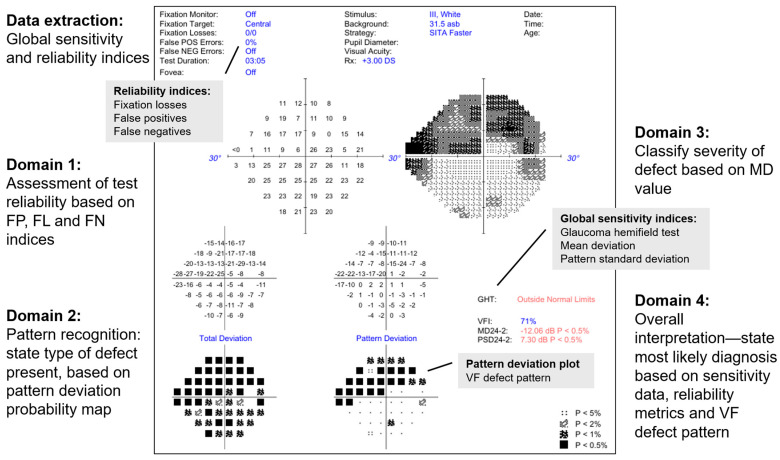
This study assesses the accuracy and consistency of a commercially available large language model (LLM) in extracting and interpreting sensitivity and reliability data from entire visual field (VF) test reports for the evaluation of glaucomatous defects. Single-page anonymised VF test reports from 60 eyes of 60 subjects were analysed by an LLM (ChatGPT 4o) across four domains-test reliability, defect type, defect severity and overall diagnosis. The main outcome measures were accuracy of data extraction, interpretation of glaucomatous field defects and diagnostic classification. The LLM displayed 100% accuracy in the extraction of global sensitivity and reliability metrics and in classifying test reliability. It also demonstrated high accuracy (96.7%) in diagnosing whether the VF defect was consistent with a healthy, suspect or glaucomatous eye. The accuracy in correctly defining the type of defect was moderate (73.3%), which only partially improved when provided with a more defined region of interest. The causes of incorrect defect type were mostly attributed to the wrong location, particularly confusing the superior and inferior hemifields. Numerical/text-based data extraction and interpretation was overall notably superior to image-based interpretation of VF defects. This study demonstrates the potential and also limitations of multimodal LLMs in processing multimodal medical investigation data such as VF reports.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


