Arum Choi, Hyun Gi Kim, Moon Hyung Choi, Shakthi Kumaran Ramasamy, Youme Kim, Seung Eun Jung
{"title":"Performance of GPT-4 Turbo and GPT-4o in Korean Society of Radiology In-Training Examinations.","authors":"Arum Choi, Hyun Gi Kim, Moon Hyung Choi, Shakthi Kumaran Ramasamy, Youme Kim, Seung Eun Jung","doi":"10.3348/kjr.2024.1096","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>Despite the potential of large language models for radiology training, their ability to handle image-based radiological questions remains poorly understood. This study aimed to evaluate the performance of the GPT-4 Turbo and GPT-4o in radiology resident examinations, to analyze differences across question types, and to compare their results with those of residents at different levels.</p><p><strong>Materials and methods: </strong>A total of 776 multiple-choice questions from the Korean Society of Radiology In-Training Examinations were used, forming two question sets: one originally written in Korean and the other translated into English. We evaluated the performance of GPT-4 Turbo (gpt-4-turbo-2024-04-09) and GPT-4o (gpt-4o-2024-11-20) on these questions with the temperature set to zero, determining the accuracy based on the majority vote from five independent trials. We analyzed their results using the question type (text-only vs. image-based) and benchmarked them against nationwide radiology residents' performance. The impact of the input language (Korean or English) on model performance was examined.</p><p><strong>Results: </strong>GPT-4o outperformed GPT-4 Turbo for both image-based (48.2% vs. 41.8%, <i>P</i> = 0.002) and text-only questions (77.9% vs. 69.0%, <i>P</i> = 0.031). On image-based questions, GPT-4 Turbo and GPT-4o showed comparable performance to that of 1st-year residents (41.8% and 48.2%, respectively, vs. 43.3%, <i>P</i> = 0.608 and 0.079, respectively) but lower performance than that of 2nd- to 4th-year residents (vs. 56.0%-63.9%, all <i>P</i> ≤ 0.005). For text-only questions, GPT-4 Turbo and GPT-4o performed better than residents across all years (69.0% and 77.9%, respectively, vs. 44.7%-57.5%, all <i>P</i> ≤ 0.039). Performance on the English- and Korean-version questions showed no significant differences for either model (all <i>P</i> ≥ 0.275).</p><p><strong>Conclusion: </strong>GPT-4o outperformed the GPT-4 Turbo in all question types. On image-based questions, both models' performance matched that of 1st-year residents but was lower than that of higher-year residents. Both models demonstrated superior performance compared to residents for text-only questions. The models showed consistent performances across English and Korean inputs.</p>","PeriodicalId":17881,"journal":{"name":"Korean Journal of Radiology","volume":" ","pages":"524-531"},"PeriodicalIF":5.3000,"publicationDate":"2025-06-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12123083/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Korean Journal of Radiology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3348/kjr.2024.1096","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/4/17 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
引用次数: 0
Abstract
Objective: Despite the potential of large language models for radiology training, their ability to handle image-based radiological questions remains poorly understood. This study aimed to evaluate the performance of the GPT-4 Turbo and GPT-4o in radiology resident examinations, to analyze differences across question types, and to compare their results with those of residents at different levels.
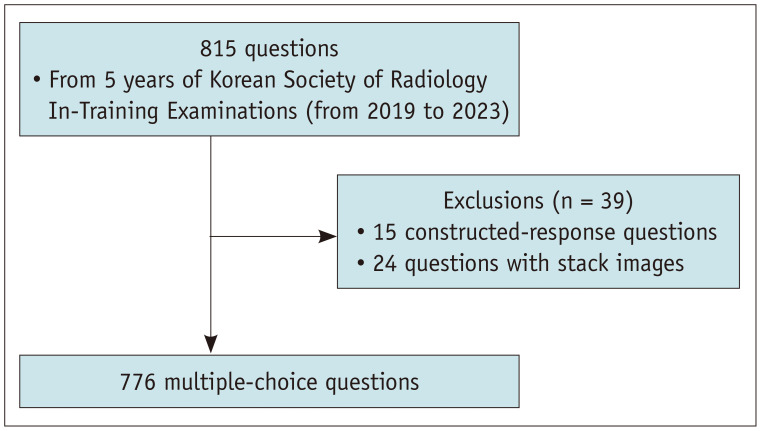
Materials and methods: A total of 776 multiple-choice questions from the Korean Society of Radiology In-Training Examinations were used, forming two question sets: one originally written in Korean and the other translated into English. We evaluated the performance of GPT-4 Turbo (gpt-4-turbo-2024-04-09) and GPT-4o (gpt-4o-2024-11-20) on these questions with the temperature set to zero, determining the accuracy based on the majority vote from five independent trials. We analyzed their results using the question type (text-only vs. image-based) and benchmarked them against nationwide radiology residents' performance. The impact of the input language (Korean or English) on model performance was examined.
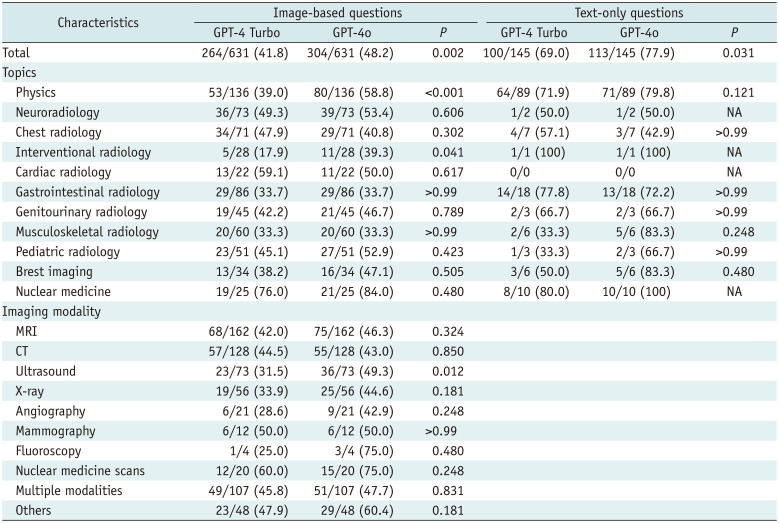
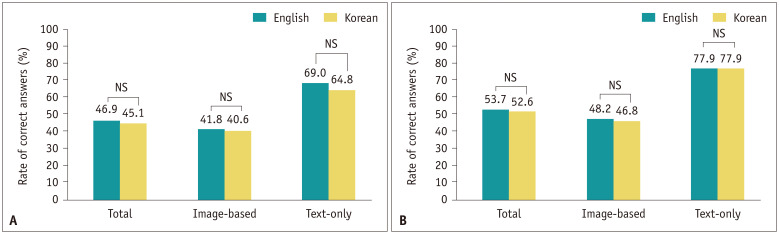
Results: GPT-4o outperformed GPT-4 Turbo for both image-based (48.2% vs. 41.8%, P = 0.002) and text-only questions (77.9% vs. 69.0%, P = 0.031). On image-based questions, GPT-4 Turbo and GPT-4o showed comparable performance to that of 1st-year residents (41.8% and 48.2%, respectively, vs. 43.3%, P = 0.608 and 0.079, respectively) but lower performance than that of 2nd- to 4th-year residents (vs. 56.0%-63.9%, all P ≤ 0.005). For text-only questions, GPT-4 Turbo and GPT-4o performed better than residents across all years (69.0% and 77.9%, respectively, vs. 44.7%-57.5%, all P ≤ 0.039). Performance on the English- and Korean-version questions showed no significant differences for either model (all P ≥ 0.275).
Conclusion: GPT-4o outperformed the GPT-4 Turbo in all question types. On image-based questions, both models' performance matched that of 1st-year residents but was lower than that of higher-year residents. Both models demonstrated superior performance compared to residents for text-only questions. The models showed consistent performances across English and Korean inputs.
期刊介绍:
The inaugural issue of the Korean J Radiol came out in March 2000. Our journal aims to produce and propagate knowledge on radiologic imaging and related sciences.
A unique feature of the articles published in the Journal will be their reflection of global trends in radiology combined with an East-Asian perspective. Geographic differences in disease prevalence will be reflected in the contents of papers, and this will serve to enrich our body of knowledge.
World''s outstanding radiologists from many countries are serving as editorial board of our journal.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


