Brenton T Bicknell, Nicholas J Rivers, Adam Skelton, Delaney Sheehan, Charis Hodges, Stevan C Fairburn, Benjamin J Greene, Bharat Panuganti
{"title":"Domain-Specific Customization for Language Models in Otolaryngology: The ENT GPT Assistant.","authors":"Brenton T Bicknell, Nicholas J Rivers, Adam Skelton, Delaney Sheehan, Charis Hodges, Stevan C Fairburn, Benjamin J Greene, Bharat Panuganti","doi":"10.1002/oto2.70125","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>To develop and evaluate the effectiveness of domain-specific customization in large language models (LLMs) by assessing the performance of the ENT GPT Assistant (E-GPT-A), a model specifically tailored for otolaryngology.</p><p><strong>Study design: </strong>Comparative analysis using multiple-choice questions (MCQs) from established otolaryngology resources.</p><p><strong>Setting: </strong>Tertiary care academic hospital.</p><p><strong>Methods: </strong>Two hundred forty clinical-vignette style MCQs were sourced from BoardVitals Otolaryngology and OTOQuest, covering a range of otolaryngology subspecialties (n = 40 for each). The E-GPT-A was developed using targeted instructions and customized to otolaryngology. The performance of E-GPT-A was compared against top-performing and widely used artificial intelligence (AI) LLMs, including GPT-3.5, GPT-4, Claude 2.0, and Claude 2.1. Accuracy was assessed across subspecialties, varying question difficulty tiers, and in diagnostics and management.</p><p><strong>Results: </strong>E-GPT-A achieved an overall accuracy of 74.6%, outperforming GPT-3.5 (60.4%), Claude 2.0 (61.7%), Claude 2.1 (60.8%), and GPT-4 (68.3%). The model performed best in allergy and rhinology (85.0%) and laryngology (82.5%), whereas showing lower accuracy in pediatrics (62.5%) and facial plastics/reconstructive surgery (67.5%). Accuracy also declined as question difficulty increased. The average correct response percentage among otolaryngologists and otolaryngology trainees was 71.1% in the question set.</p><p><strong>Conclusion: </strong>This pilot study using the E-GPT-A demonstrates the potential benefits of domain-specific customizations of language models for otolaryngology. However, further development, continuous updates, and continued real-world validation are needed to fully assess the capabilities of LLMs in otolaryngology.</p>","PeriodicalId":19697,"journal":{"name":"OTO Open","volume":"9 2","pages":"e70125"},"PeriodicalIF":1.8000,"publicationDate":"2025-05-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12051367/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"OTO Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1002/oto2.70125","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/4/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"OTORHINOLARYNGOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Objective: To develop and evaluate the effectiveness of domain-specific customization in large language models (LLMs) by assessing the performance of the ENT GPT Assistant (E-GPT-A), a model specifically tailored for otolaryngology.
Study design: Comparative analysis using multiple-choice questions (MCQs) from established otolaryngology resources.
Setting: Tertiary care academic hospital.
Methods: Two hundred forty clinical-vignette style MCQs were sourced from BoardVitals Otolaryngology and OTOQuest, covering a range of otolaryngology subspecialties (n = 40 for each). The E-GPT-A was developed using targeted instructions and customized to otolaryngology. The performance of E-GPT-A was compared against top-performing and widely used artificial intelligence (AI) LLMs, including GPT-3.5, GPT-4, Claude 2.0, and Claude 2.1. Accuracy was assessed across subspecialties, varying question difficulty tiers, and in diagnostics and management.
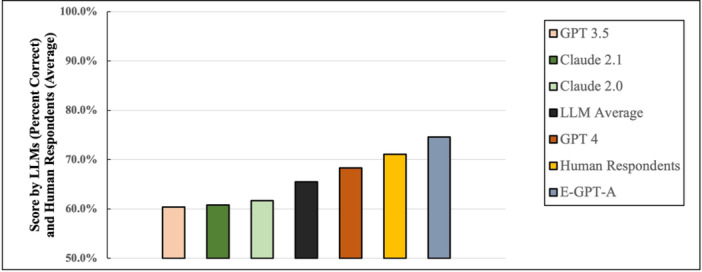
Results: E-GPT-A achieved an overall accuracy of 74.6%, outperforming GPT-3.5 (60.4%), Claude 2.0 (61.7%), Claude 2.1 (60.8%), and GPT-4 (68.3%). The model performed best in allergy and rhinology (85.0%) and laryngology (82.5%), whereas showing lower accuracy in pediatrics (62.5%) and facial plastics/reconstructive surgery (67.5%). Accuracy also declined as question difficulty increased. The average correct response percentage among otolaryngologists and otolaryngology trainees was 71.1% in the question set.
Conclusion: This pilot study using the E-GPT-A demonstrates the potential benefits of domain-specific customizations of language models for otolaryngology. However, further development, continuous updates, and continued real-world validation are needed to fully assess the capabilities of LLMs in otolaryngology.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


