{"title":"Assessment of artificial intelligence performance in answering questions on onabotulinum toxin and sacral neuromodulation.","authors":"Ibrahim Hacibey, Ahmet Halis","doi":"10.4111/icu.20250040","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>This study aimed to evaluate the performance of three artificial intelligence (AI) models-ChatGPT, Gemini, and Copilot-in addressing clinically relevant questions about onabotulinum toxin and sacral neuromodulation (SNM) for the management of overactive bladder (OAB).</p><p><strong>Materials and methods: </strong>A set of 30 questions covering mechanisms of action, indications, contraindications, procedural details, efficacy, and safety profiles was posed to each AI model. Responses were assessed by a panel of four urology specialists using predefined criteria: accuracy, completeness, clarity, and consistency. A multi-dimensional scoring framework evaluated the performance across five dimensions: factual accuracy, relevance, clarity/coherence, structure, and utility. Responses were scored on a 4-point Likert scale, and statistical analyses were conducted using one-way ANOVA to compare model performance.</p><p><strong>Results: </strong>ChatGPT achieved the highest mean score (3.98/4) across all dimensions, with statistically significant differences compared to Gemini (3.20/4) and Copilot (2.60/4) (p=0.001 for all dimensions). ChatGPT excelled particularly in clinical application, procedure, and safety categories, consistently delivering accurate and comprehensive answers. No statistically significant differences were found between Gemini and Copilot in most categories.</p><p><strong>Conclusions: </strong>ChatGPT demonstrated superior performance in generating accurate, complete, and clinically relevant responses for OAB management, highlighting its potential as a reliable tool for both healthcare professionals and patients. However, the variability observed in Gemini and Copilot underscores the need for further refinement of these models. Future studies should explore real-world integration of AI models into clinical workflows to enhance patient care and decision-making.</p>","PeriodicalId":14522,"journal":{"name":"Investigative and Clinical Urology","volume":"66 3","pages":"188-193"},"PeriodicalIF":2.1000,"publicationDate":"2025-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12058535/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Investigative and Clinical Urology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.4111/icu.20250040","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"UROLOGY & NEPHROLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Purpose: This study aimed to evaluate the performance of three artificial intelligence (AI) models-ChatGPT, Gemini, and Copilot-in addressing clinically relevant questions about onabotulinum toxin and sacral neuromodulation (SNM) for the management of overactive bladder (OAB).
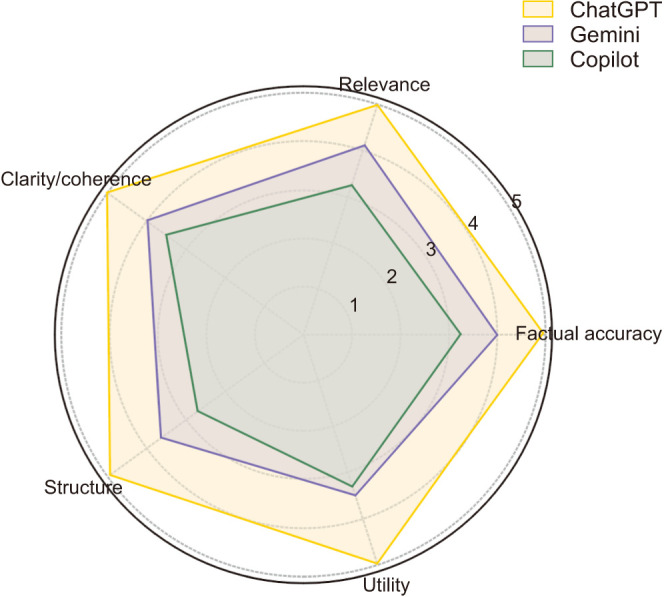
Materials and methods: A set of 30 questions covering mechanisms of action, indications, contraindications, procedural details, efficacy, and safety profiles was posed to each AI model. Responses were assessed by a panel of four urology specialists using predefined criteria: accuracy, completeness, clarity, and consistency. A multi-dimensional scoring framework evaluated the performance across five dimensions: factual accuracy, relevance, clarity/coherence, structure, and utility. Responses were scored on a 4-point Likert scale, and statistical analyses were conducted using one-way ANOVA to compare model performance.
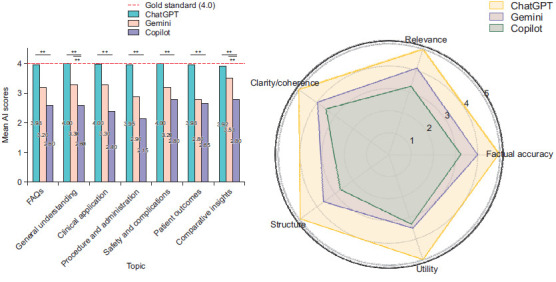
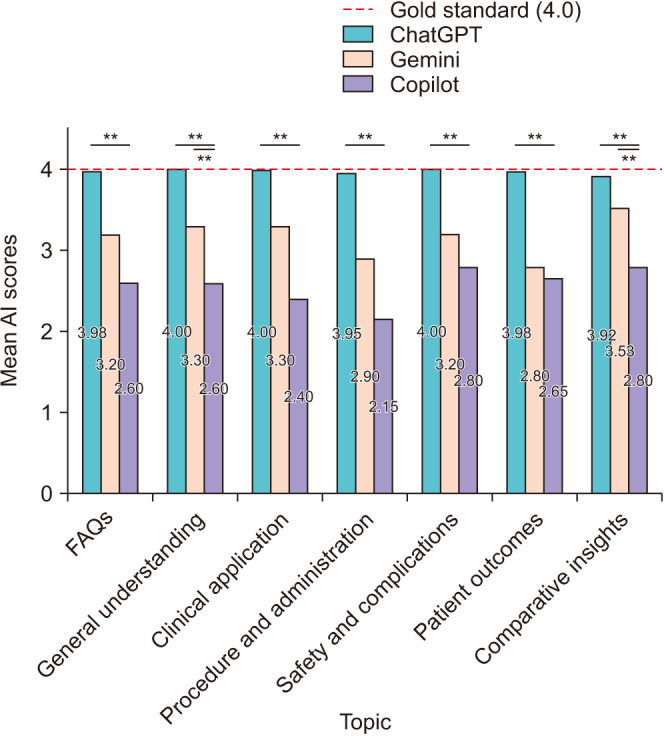
Results: ChatGPT achieved the highest mean score (3.98/4) across all dimensions, with statistically significant differences compared to Gemini (3.20/4) and Copilot (2.60/4) (p=0.001 for all dimensions). ChatGPT excelled particularly in clinical application, procedure, and safety categories, consistently delivering accurate and comprehensive answers. No statistically significant differences were found between Gemini and Copilot in most categories.
Conclusions: ChatGPT demonstrated superior performance in generating accurate, complete, and clinically relevant responses for OAB management, highlighting its potential as a reliable tool for both healthcare professionals and patients. However, the variability observed in Gemini and Copilot underscores the need for further refinement of these models. Future studies should explore real-world integration of AI models into clinical workflows to enhance patient care and decision-making.
期刊介绍:
Investigative and Clinical Urology (Investig Clin Urol, ICUrology) is an international, peer-reviewed, platinum open access journal published bimonthly. ICUrology aims to provide outstanding scientific and clinical research articles, that will advance knowledge and understanding of urological diseases and current therapeutic treatments. ICUrology publishes Original Articles, Rapid Communications, Review Articles, Special Articles, Innovations in Urology, Editorials, and Letters to the Editor, with a focus on the following areas of expertise:
• Precision Medicine in Urology
• Urological Oncology
• Robotics/Laparoscopy
• Endourology/Urolithiasis
• Lower Urinary Tract Dysfunction
• Female Urology
• Sexual Dysfunction/Infertility
• Infection/Inflammation
• Reconstruction/Transplantation
• Geriatric Urology
• Pediatric Urology
• Basic/Translational Research
One of the notable features of ICUrology is the application of multimedia platforms facilitating easy-to-access online video clips of newly developed surgical techniques from the journal''s website, by a QR (quick response) code located in the article, or via YouTube. ICUrology provides current and highly relevant knowledge to a broad audience at the cutting edge of urological research and clinical practice.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


