Jackson Woodrow, Nour Nassour, John Y Kwon, Soheil Ashkani-Esfahani, Mitchel Harris
{"title":"From Algorithms to Academia: An Endeavor to Benchmark AI-Generated Scientific Papers against Human Standards.","authors":"Jackson Woodrow, Nour Nassour, John Y Kwon, Soheil Ashkani-Esfahani, Mitchel Harris","doi":"10.22038/ABJS.2024.80093.3669","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>The aim of this study is to quantitatively investigate the accuracy of text generated by AI large language models while comparing their readability and likelihood of being accepted to a scientific compared to human-authored papers on the same topics.</p><p><strong>Methods: </strong>The study consisted of two papers written by ChatGPT, two papers written by Assistant by scite, and two papers written by humans. A total of six independent reviewers were blinded to the authorship of each paper and assigned a grade to each subsection on a scale of 1 to 4. Additionally, each reviewer was asked to guess if the paper was written by a human or AI and explain their reasoning. The study authors also graded each AI-generated paper based on factual accuracy of the claims and citations.</p><p><strong>Results: </strong>The human-written calcaneus fracture paper received the highest score of a 3.70/4, followed by Assistant-written calcaneus fracture paper (3.02/4), human-written ankle osteoarthritis paper (2.98/4), ChatGPT calcaneus fracture (2.89/4), ChatGPT Ankle Osteoarthritis (2.87/4), and Assistant Ankle Osteoarthritis (2.78/4). The human calcaneus fracture paper received a statistically significant higher rating than the ChatGPT calcaneus fracture paper (P = 0.028) and the Assistant calcaneus fracture paper (P = 0.043). The ChatGPT osteoarthritis review showed 100% factual accuracy, the ChatGPT calcaneus fracture review was 97.46% factually accurate, the Assistant calcaneus fracture was 95.56% accurate, and the Assistant ankle osteoarthritis was 94.98% accurate. Regarding citations, the ChatGPT ankle osteoarthritis paper was 90% accurate, the ChatGPT calcaneus fracture was 69.23% accurate, the Assistant ankle osteoarthritis was 35.14% accurate, and the Assistant calcaneus fracture was 39.68% accurate.</p><p><strong>Conclusion: </strong>Through this paper we emphasize that while AI holds the promise of enhancing knowledge sharing, it must be used responsibly and in conjunction with comprehensive fact-checking procedures to maintain the integrity of the scientific discourse.</p>","PeriodicalId":46704,"journal":{"name":"Archives of Bone and Joint Surgery-ABJS","volume":"13 4","pages":"212-222"},"PeriodicalIF":1.8000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12050080/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Archives of Bone and Joint Surgery-ABJS","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.22038/ABJS.2024.80093.3669","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"ORTHOPEDICS","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: The aim of this study is to quantitatively investigate the accuracy of text generated by AI large language models while comparing their readability and likelihood of being accepted to a scientific compared to human-authored papers on the same topics.
Methods: The study consisted of two papers written by ChatGPT, two papers written by Assistant by scite, and two papers written by humans. A total of six independent reviewers were blinded to the authorship of each paper and assigned a grade to each subsection on a scale of 1 to 4. Additionally, each reviewer was asked to guess if the paper was written by a human or AI and explain their reasoning. The study authors also graded each AI-generated paper based on factual accuracy of the claims and citations.
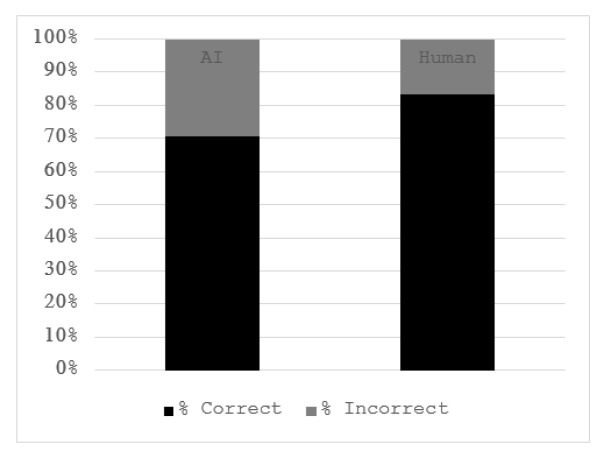
Results: The human-written calcaneus fracture paper received the highest score of a 3.70/4, followed by Assistant-written calcaneus fracture paper (3.02/4), human-written ankle osteoarthritis paper (2.98/4), ChatGPT calcaneus fracture (2.89/4), ChatGPT Ankle Osteoarthritis (2.87/4), and Assistant Ankle Osteoarthritis (2.78/4). The human calcaneus fracture paper received a statistically significant higher rating than the ChatGPT calcaneus fracture paper (P = 0.028) and the Assistant calcaneus fracture paper (P = 0.043). The ChatGPT osteoarthritis review showed 100% factual accuracy, the ChatGPT calcaneus fracture review was 97.46% factually accurate, the Assistant calcaneus fracture was 95.56% accurate, and the Assistant ankle osteoarthritis was 94.98% accurate. Regarding citations, the ChatGPT ankle osteoarthritis paper was 90% accurate, the ChatGPT calcaneus fracture was 69.23% accurate, the Assistant ankle osteoarthritis was 35.14% accurate, and the Assistant calcaneus fracture was 39.68% accurate.
Conclusion: Through this paper we emphasize that while AI holds the promise of enhancing knowledge sharing, it must be used responsibly and in conjunction with comprehensive fact-checking procedures to maintain the integrity of the scientific discourse.
期刊介绍:
The Archives of Bone and Joint Surgery (ABJS) aims to encourage a better understanding of all aspects of Orthopedic Sciences. The journal accepts scientific papers including original research, review article, short communication, case report, and letter to the editor in all fields of bone, joint, musculoskeletal surgery and related researches. The Archives of Bone and Joint Surgery (ABJS) will publish papers in all aspects of today`s modern orthopedic sciences including: Arthroscopy, Arthroplasty, Sport Medicine, Reconstruction, Hand and Upper Extremity, Pediatric Orthopedics, Spine, Trauma, Foot and Ankle, Tumor, Joint Rheumatic Disease, Skeletal Imaging, Orthopedic Physical Therapy, Rehabilitation, Orthopedic Basic Sciences (Biomechanics, Biotechnology, Biomaterial..).

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


