Sahana Srinivasan, Hongwei Ji, David Ziyou Chen, Wendy Wong, Zhi Da Soh, Jocelyn Hui Lin Goh, Krithi Pushpanathan, Xiaofei Wang, Weizhi Ma, Tien Yin Wong, Ya Xing Wang, Ching-Yu Cheng, Yih Chung Tham
{"title":"Can off-the-shelf visual large language models detect and diagnose ocular diseases from retinal photographs?","authors":"Sahana Srinivasan, Hongwei Ji, David Ziyou Chen, Wendy Wong, Zhi Da Soh, Jocelyn Hui Lin Goh, Krithi Pushpanathan, Xiaofei Wang, Weizhi Ma, Tien Yin Wong, Ya Xing Wang, Ching-Yu Cheng, Yih Chung Tham","doi":"10.1136/bmjophth-2024-002076","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The advent of generative artificial intelligence has led to the emergence of multiple vision large language models (VLLMs). This study aimed to evaluate the capabilities of commonly available VLLMs, such as OpenAI's GPT-4V and Google's Gemini, in detecting and diagnosing ocular diseases from retinal images.</p><p><strong>Methods and analysis: </strong>From the Singapore Epidemiology of Eye Diseases (SEED) study, we selected 44 representative retinal photographs, including 10 healthy and 34 representing six eye diseases (age-related macular degeneration, diabetic retinopathy, glaucoma, visually significant cataract, myopic macular degeneration and retinal vein occlusion). OpenAI's GPT-4V (both default and data analyst modes) and Google Gemini were prompted with each image to determine if the retina was normal or abnormal and to provide diagnostic descriptions if deemed abnormal. The outputs from the VLLMs were evaluated for accuracy by three attending-level ophthalmologists using a three-point scale (poor, borderline, good).</p><p><strong>Results: </strong>GPT-4V default mode demonstrated the highest detection rate, correctly identifying 33 out of 34 detected correctly (97.1%), outperforming its data analyst mode (61.8%) and Google Gemini (41.2%). Despite the relatively high detection rates, the quality of diagnostic descriptions was generally suboptimal-with only 21.2% of GPT-4V's (default) responses, 4.8% of GPT-4V's (data analyst) responses and 28.6% for Google Gemini's responses rated as good.</p><p><strong>Conclusions: </strong>Although GPT-4V default mode showed generally high sensitivity in abnormality detection, all evaluated VLLMs were inadequate in providing accurate diagnoses for ocular diseases. These findings emphasise the need for domain-customised VLLMs and suggest the continued need for human oversight in clinical ophthalmology.</p>","PeriodicalId":9286,"journal":{"name":"BMJ Open Ophthalmology","volume":"10 1","pages":""},"PeriodicalIF":2.2000,"publicationDate":"2025-04-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11977474/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Open Ophthalmology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjophth-2024-002076","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"OPHTHALMOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The advent of generative artificial intelligence has led to the emergence of multiple vision large language models (VLLMs). This study aimed to evaluate the capabilities of commonly available VLLMs, such as OpenAI's GPT-4V and Google's Gemini, in detecting and diagnosing ocular diseases from retinal images.
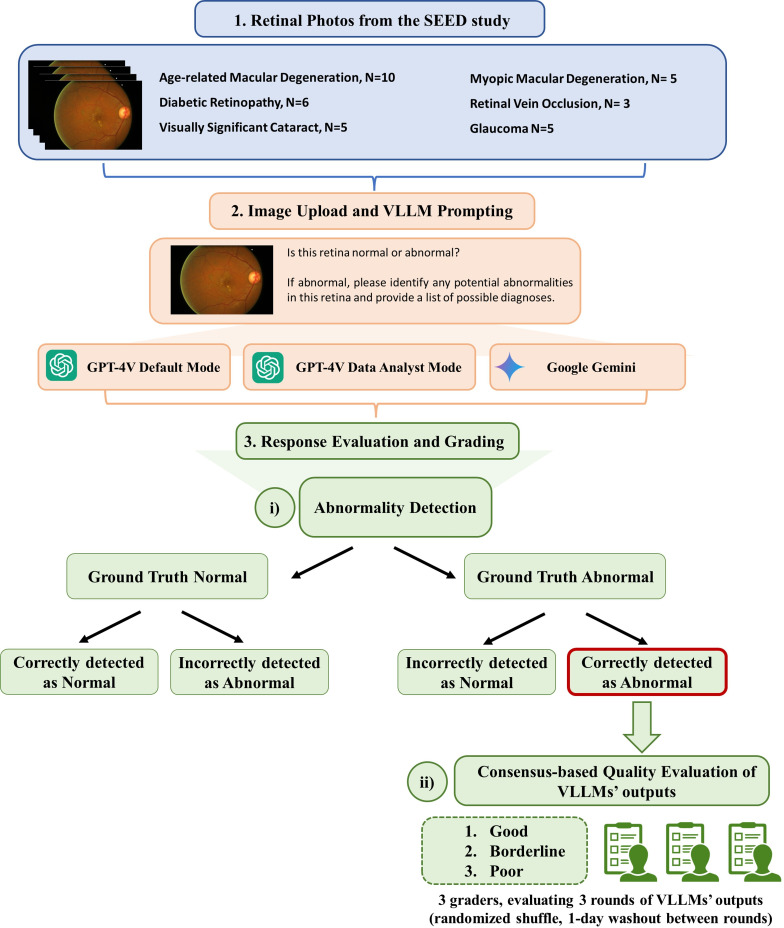
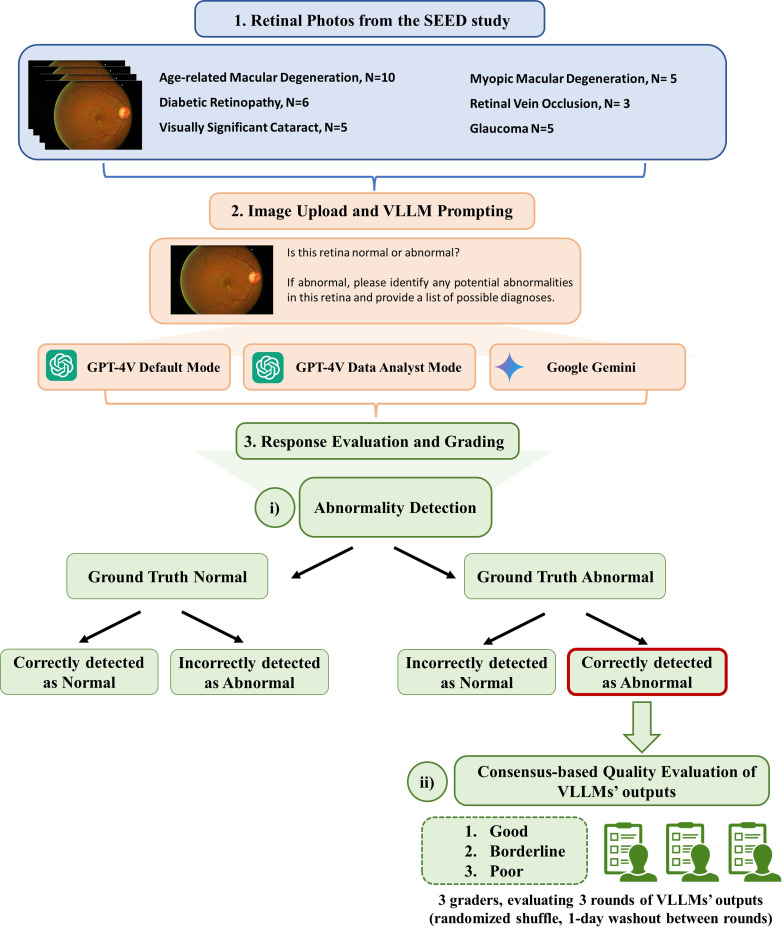
Methods and analysis: From the Singapore Epidemiology of Eye Diseases (SEED) study, we selected 44 representative retinal photographs, including 10 healthy and 34 representing six eye diseases (age-related macular degeneration, diabetic retinopathy, glaucoma, visually significant cataract, myopic macular degeneration and retinal vein occlusion). OpenAI's GPT-4V (both default and data analyst modes) and Google Gemini were prompted with each image to determine if the retina was normal or abnormal and to provide diagnostic descriptions if deemed abnormal. The outputs from the VLLMs were evaluated for accuracy by three attending-level ophthalmologists using a three-point scale (poor, borderline, good).
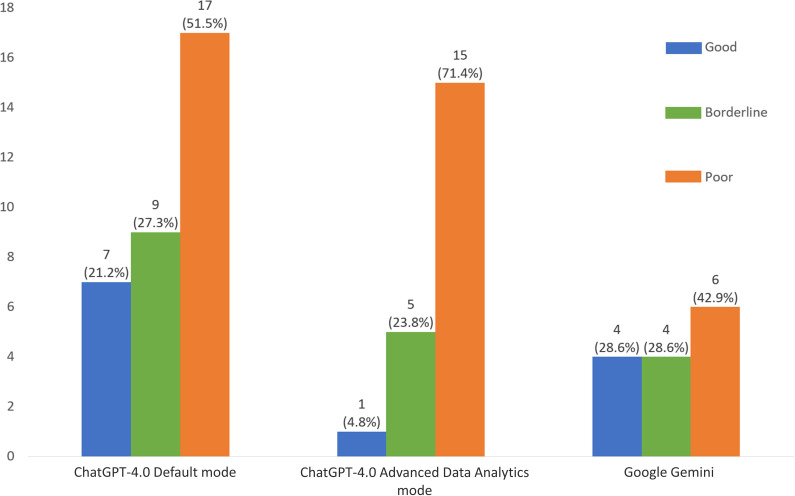
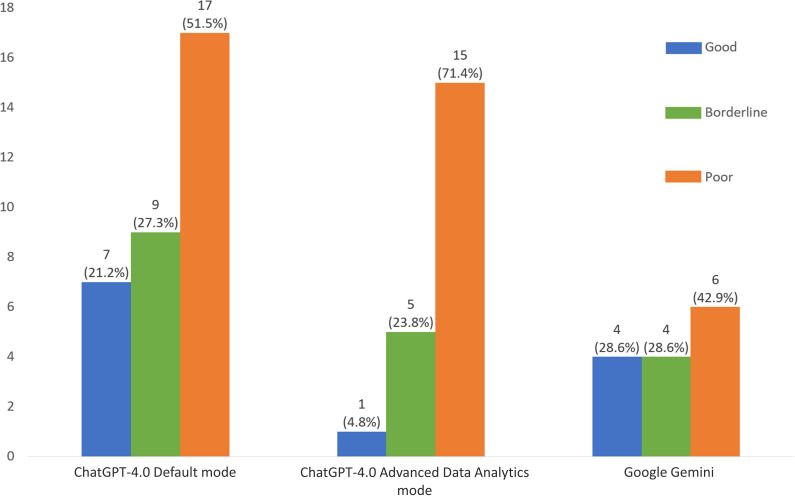
Results: GPT-4V default mode demonstrated the highest detection rate, correctly identifying 33 out of 34 detected correctly (97.1%), outperforming its data analyst mode (61.8%) and Google Gemini (41.2%). Despite the relatively high detection rates, the quality of diagnostic descriptions was generally suboptimal-with only 21.2% of GPT-4V's (default) responses, 4.8% of GPT-4V's (data analyst) responses and 28.6% for Google Gemini's responses rated as good.
Conclusions: Although GPT-4V default mode showed generally high sensitivity in abnormality detection, all evaluated VLLMs were inadequate in providing accurate diagnoses for ocular diseases. These findings emphasise the need for domain-customised VLLMs and suggest the continued need for human oversight in clinical ophthalmology.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


