Siyu Han, Shixiang Yu, Mengya Shi, Makoto Harada, Jianhong Ge, Jiesheng Lin, Cornelia Prehn, Agnese Petrera, Ying Li, Flora Sam, Giuseppe Matullo, Jerzy Adamski, Karsten Suhre, Christian Gieger, Stefanie M. Hauck, Christian Herder, Michael Roden, Francesco Paolo Casale, Na Cai, Annette Peters, Rui Wang-Sattler
{"title":"LEOPARD: missing view completion for multi-timepoint omics data via representation disentanglement and temporal knowledge transfer","authors":"Siyu Han, Shixiang Yu, Mengya Shi, Makoto Harada, Jianhong Ge, Jiesheng Lin, Cornelia Prehn, Agnese Petrera, Ying Li, Flora Sam, Giuseppe Matullo, Jerzy Adamski, Karsten Suhre, Christian Gieger, Stefanie M. Hauck, Christian Herder, Michael Roden, Francesco Paolo Casale, Na Cai, Annette Peters, Rui Wang-Sattler","doi":"10.1038/s41467-025-58314-3","DOIUrl":null,"url":null,"abstract":"<p>Longitudinal multi-view omics data offer unique insights into the temporal dynamics of individual-level physiology, which provides opportunities to advance personalized healthcare. However, the common occurrence of incomplete views makes extrapolation tasks difficult, and there is a lack of tailored methods for this critical issue. Here, we introduce LEOPARD, an innovative approach specifically designed to complete missing views in multi-timepoint omics data. By disentangling longitudinal omics data into content and temporal representations, LEOPARD transfers the temporal knowledge to the omics-specific content, thereby completing missing views. The effectiveness of LEOPARD is validated on four real-world omics datasets constructed with data from the MGH COVID study and the KORA cohort, spanning periods from 3 days to 14 years. Compared to conventional imputation methods, such as missForest, PMM, GLMM, and cGAN, LEOPARD yields the most robust results across the benchmark datasets. LEOPARD-imputed data also achieve the highest agreement with observed data in our analyses for age-associated metabolites detection, estimated glomerular filtration rate-associated proteins identification, and chronic kidney disease prediction. Our work takes the first step toward a generalized treatment of missing views in longitudinal omics data, enabling comprehensive exploration of temporal dynamics and providing valuable insights into personalized healthcare.</p>","PeriodicalId":19066,"journal":{"name":"Nature Communications","volume":"217 1","pages":""},"PeriodicalIF":15.7000,"publicationDate":"2025-04-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Communications","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41467-025-58314-3","RegionNum":1,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
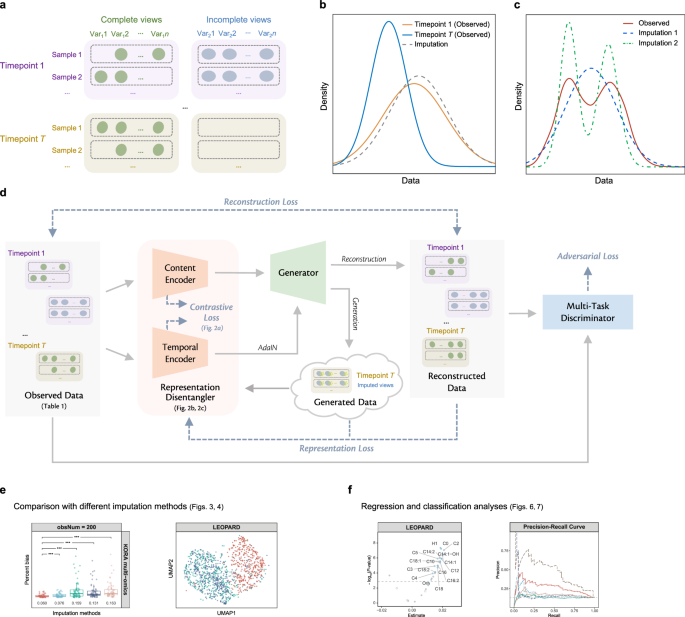
Longitudinal multi-view omics data offer unique insights into the temporal dynamics of individual-level physiology, which provides opportunities to advance personalized healthcare. However, the common occurrence of incomplete views makes extrapolation tasks difficult, and there is a lack of tailored methods for this critical issue. Here, we introduce LEOPARD, an innovative approach specifically designed to complete missing views in multi-timepoint omics data. By disentangling longitudinal omics data into content and temporal representations, LEOPARD transfers the temporal knowledge to the omics-specific content, thereby completing missing views. The effectiveness of LEOPARD is validated on four real-world omics datasets constructed with data from the MGH COVID study and the KORA cohort, spanning periods from 3 days to 14 years. Compared to conventional imputation methods, such as missForest, PMM, GLMM, and cGAN, LEOPARD yields the most robust results across the benchmark datasets. LEOPARD-imputed data also achieve the highest agreement with observed data in our analyses for age-associated metabolites detection, estimated glomerular filtration rate-associated proteins identification, and chronic kidney disease prediction. Our work takes the first step toward a generalized treatment of missing views in longitudinal omics data, enabling comprehensive exploration of temporal dynamics and providing valuable insights into personalized healthcare.
期刊介绍:
Nature Communications, an open-access journal, publishes high-quality research spanning all areas of the natural sciences. Papers featured in the journal showcase significant advances relevant to specialists in each respective field. With a 2-year impact factor of 16.6 (2022) and a median time of 8 days from submission to the first editorial decision, Nature Communications is committed to rapid dissemination of research findings. As a multidisciplinary journal, it welcomes contributions from biological, health, physical, chemical, Earth, social, mathematical, applied, and engineering sciences, aiming to highlight important breakthroughs within each domain.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


