Heidi C Ventresca, Harley T Davis, Chase W Gauthier, Justin Kung, Joseph S Park, Nicholas L Strasser, Tyler A Gonzalez, J Benjamin Jackson
{"title":"ChatGPT-4 Effectively Responds to Common Patient Questions on Total Ankle Arthroplasty: A Surgeon-Based Assessment of AI in Patient Education.","authors":"Heidi C Ventresca, Harley T Davis, Chase W Gauthier, Justin Kung, Joseph S Park, Nicholas L Strasser, Tyler A Gonzalez, J Benjamin Jackson","doi":"10.1177/24730114251322784","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Patient reliance on internet resources for clinical information has steadily increased. The recent widespread accessibility of artificial intelligence (AI) tools like ChatGPT has increased patient reliance on these resources while also raising concerns about the accuracy, reliability, and appropriateness of the information they provide. Previous studies have evaluated ChatGPT and found it could accurately respond to questions on common surgeries, such as total hip arthroplasty, but is untested for uncommon procedures like total ankle arthroplasty (TAA). This study evaluates ChatGPT-4's performance in answering patient questions on TAA and further explores the opportunity for physician involvement in guiding the implementation of this technology.</p><p><strong>Methods: </strong>Twelve commonly asked patient questions regarding TAA were collated from established sources and posed to ChatGPT-4 without additional input. Four fellowship-trained surgeons independently rated the responses using a 1-4 scale, assessing accuracy and need for clarification. Interrater reliability, divergence, and trends in response content were analyzed to evaluate consistency across responses.</p><p><strong>Results: </strong>The mean score across all responses was 1.8, indicating an overall satisfactory performance by ChatGPT-4. Ratings were consistently good on factual questions, such as infection risk and success rates, whereas questions requiring nuanced information, such as postoperative protocols and prognosis, received poorer ratings. Significant variability was observed among surgeons' ratings and between questions, reflecting differences in interpretation and expectations.</p><p><strong>Conclusion: </strong>ChatGPT-4 demonstrates its potential to reliably provide discrete information for uncommon procedures such as TAA, but it lacks the capability to effectively respond to questions requiring patient- or surgeon-specific insight. This limitation, paired with the growing reliance on AI, highlights the need for AI tools tailored to specific clinical practices to enhance accuracy and relevance in patient education.</p>","PeriodicalId":12429,"journal":{"name":"Foot & Ankle Orthopaedics","volume":"10 1","pages":"24730114251322784"},"PeriodicalIF":0.0000,"publicationDate":"2025-03-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11951880/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Foot & Ankle Orthopaedics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1177/24730114251322784","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Patient reliance on internet resources for clinical information has steadily increased. The recent widespread accessibility of artificial intelligence (AI) tools like ChatGPT has increased patient reliance on these resources while also raising concerns about the accuracy, reliability, and appropriateness of the information they provide. Previous studies have evaluated ChatGPT and found it could accurately respond to questions on common surgeries, such as total hip arthroplasty, but is untested for uncommon procedures like total ankle arthroplasty (TAA). This study evaluates ChatGPT-4's performance in answering patient questions on TAA and further explores the opportunity for physician involvement in guiding the implementation of this technology.
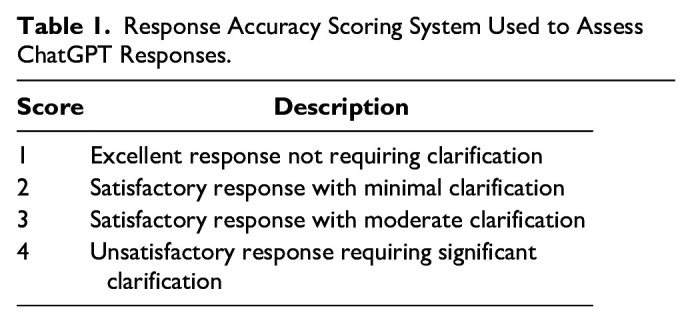
Methods: Twelve commonly asked patient questions regarding TAA were collated from established sources and posed to ChatGPT-4 without additional input. Four fellowship-trained surgeons independently rated the responses using a 1-4 scale, assessing accuracy and need for clarification. Interrater reliability, divergence, and trends in response content were analyzed to evaluate consistency across responses.
Results: The mean score across all responses was 1.8, indicating an overall satisfactory performance by ChatGPT-4. Ratings were consistently good on factual questions, such as infection risk and success rates, whereas questions requiring nuanced information, such as postoperative protocols and prognosis, received poorer ratings. Significant variability was observed among surgeons' ratings and between questions, reflecting differences in interpretation and expectations.
Conclusion: ChatGPT-4 demonstrates its potential to reliably provide discrete information for uncommon procedures such as TAA, but it lacks the capability to effectively respond to questions requiring patient- or surgeon-specific insight. This limitation, paired with the growing reliance on AI, highlights the need for AI tools tailored to specific clinical practices to enhance accuracy and relevance in patient education.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


