Salman Khan, Islam Uddin, Sumaiya Noor, Salman A AlQahtani, Nijad Ahmad
{"title":"N6-methyladenine identification using deep learning and discriminative feature integration.","authors":"Salman Khan, Islam Uddin, Sumaiya Noor, Salman A AlQahtani, Nijad Ahmad","doi":"10.1186/s12920-025-02131-6","DOIUrl":null,"url":null,"abstract":"<p><p>N6-methyladenine (6 mA) is a pivotal DNA modification that plays a crucial role in epigenetic regulation, gene expression, and various biological processes. With advancements in sequencing technologies and computational biology, there is an increasing focus on developing accurate methods for 6 mA site identification to enhance early detection and understand its biological significance. Despite the rapid progress of machine learning in bioinformatics, accurately detecting 6 mA sites remains a challenge due to the limited generalizability and efficiency of existing approaches. In this study, we present Deep-N6mA, a novel Deep Neural Network (DNN) model incorporating optimal hybrid features for precise 6 mA site identification. The proposed framework captures complex patterns from DNA sequences through a comprehensive feature extraction process, leveraging k-mer, Dinucleotide-based Cross Covariance (DCC), Trinucleotide-based Auto Covariance (TAC), Pseudo Single Nucleotide Composition (PseSNC), Pseudo Dinucleotide Composition (PseDNC), and Pseudo Trinucleotide Composition (PseTNC). To optimize computational efficiency and eliminate irrelevant or noisy features, an unsupervised Principal Component Analysis (PCA) algorithm is employed, ensuring the selection of the most informative features. A multilayer DNN serves as the classification algorithm to identify N6-methyladenine sites accurately. The robustness and generalizability of Deep-N6mA were rigorously validated using fivefold cross-validation on two benchmark datasets. Experimental results reveal that Deep-N6mA achieves an average accuracy of 97.70% on the F. vesca dataset and 95.75% on the R. chinensis dataset, outperforming existing methods by 4.12% and 4.55%, respectively. These findings underscore the effectiveness of Deep-N6mA as a reliable tool for early 6 mA site detection, contributing to epigenetic research and advancing the field of computational biology.</p>","PeriodicalId":8915,"journal":{"name":"BMC Medical Genomics","volume":"18 1","pages":"58"},"PeriodicalIF":2.0000,"publicationDate":"2025-03-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11955129/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Medical Genomics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s12920-025-02131-6","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
引用次数: 0
Abstract
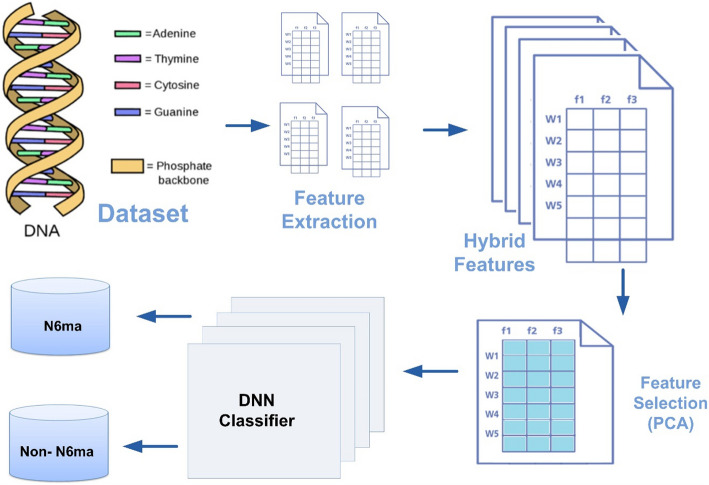
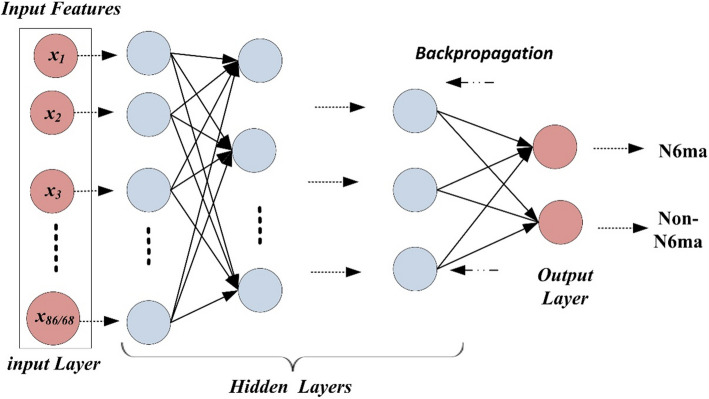
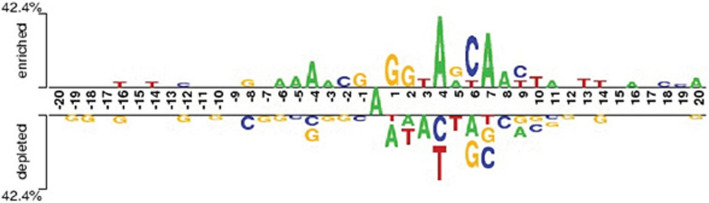
N6-methyladenine (6 mA) is a pivotal DNA modification that plays a crucial role in epigenetic regulation, gene expression, and various biological processes. With advancements in sequencing technologies and computational biology, there is an increasing focus on developing accurate methods for 6 mA site identification to enhance early detection and understand its biological significance. Despite the rapid progress of machine learning in bioinformatics, accurately detecting 6 mA sites remains a challenge due to the limited generalizability and efficiency of existing approaches. In this study, we present Deep-N6mA, a novel Deep Neural Network (DNN) model incorporating optimal hybrid features for precise 6 mA site identification. The proposed framework captures complex patterns from DNA sequences through a comprehensive feature extraction process, leveraging k-mer, Dinucleotide-based Cross Covariance (DCC), Trinucleotide-based Auto Covariance (TAC), Pseudo Single Nucleotide Composition (PseSNC), Pseudo Dinucleotide Composition (PseDNC), and Pseudo Trinucleotide Composition (PseTNC). To optimize computational efficiency and eliminate irrelevant or noisy features, an unsupervised Principal Component Analysis (PCA) algorithm is employed, ensuring the selection of the most informative features. A multilayer DNN serves as the classification algorithm to identify N6-methyladenine sites accurately. The robustness and generalizability of Deep-N6mA were rigorously validated using fivefold cross-validation on two benchmark datasets. Experimental results reveal that Deep-N6mA achieves an average accuracy of 97.70% on the F. vesca dataset and 95.75% on the R. chinensis dataset, outperforming existing methods by 4.12% and 4.55%, respectively. These findings underscore the effectiveness of Deep-N6mA as a reliable tool for early 6 mA site detection, contributing to epigenetic research and advancing the field of computational biology.
期刊介绍:
BMC Medical Genomics is an open access journal publishing original peer-reviewed research articles in all aspects of functional genomics, genome structure, genome-scale population genetics, epigenomics, proteomics, systems analysis, and pharmacogenomics in relation to human health and disease.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


