{"title":"Performance of ChatGPT-4 on Taiwanese Traditional Chinese Medicine Licensing Examinations: Cross-Sectional Study.","authors":"Liang-Wei Tseng, Yi-Chin Lu, Liang-Chi Tseng, Yu-Chun Chen, Hsing-Yu Chen","doi":"10.2196/58897","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The integration of artificial intelligence (AI), notably ChatGPT, into medical education, has shown promising results in various medical fields. Nevertheless, its efficacy in traditional Chinese medicine (TCM) examinations remains understudied.</p><p><strong>Objective: </strong>This study aims to (1) assess the performance of ChatGPT on the TCM licensing examination in Taiwan and (2) evaluate the model's explainability in answering TCM-related questions to determine its suitability as a TCM learning tool.</p><p><strong>Methods: </strong>We used the GPT-4 model to respond to 480 questions from the 2022 TCM licensing examination. This study compared the performance of the model against that of licensed TCM doctors using 2 approaches, namely direct answer selection and provision of explanations before answer selection. The accuracy and consistency of AI-generated responses were analyzed. Moreover, a breakdown of question characteristics was performed based on the cognitive level, depth of knowledge, types of questions, vignette style, and polarity of questions.</p><p><strong>Results: </strong>ChatGPT achieved an overall accuracy of 43.9%, which was lower than that of 2 human participants (70% and 78.4%). The analysis did not reveal a significant correlation between the accuracy of the model and the characteristics of the questions. An in-depth examination indicated that errors predominantly resulted from a misunderstanding of TCM concepts (55.3%), emphasizing the limitations of the model with regard to its TCM knowledge base and reasoning capability.</p><p><strong>Conclusions: </strong>Although ChatGPT shows promise as an educational tool, its current performance on TCM licensing examinations is lacking. This highlights the need for enhancing AI models with specialized TCM training and suggests a cautious approach to utilizing AI for TCM education. Future research should focus on model improvement and the development of tailored educational applications to support TCM learning.</p>","PeriodicalId":36236,"journal":{"name":"JMIR Medical Education","volume":"11 ","pages":"e58897"},"PeriodicalIF":3.2000,"publicationDate":"2025-03-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11939018/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Education","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/58897","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"EDUCATION, SCIENTIFIC DISCIPLINES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The integration of artificial intelligence (AI), notably ChatGPT, into medical education, has shown promising results in various medical fields. Nevertheless, its efficacy in traditional Chinese medicine (TCM) examinations remains understudied.
Objective: This study aims to (1) assess the performance of ChatGPT on the TCM licensing examination in Taiwan and (2) evaluate the model's explainability in answering TCM-related questions to determine its suitability as a TCM learning tool.
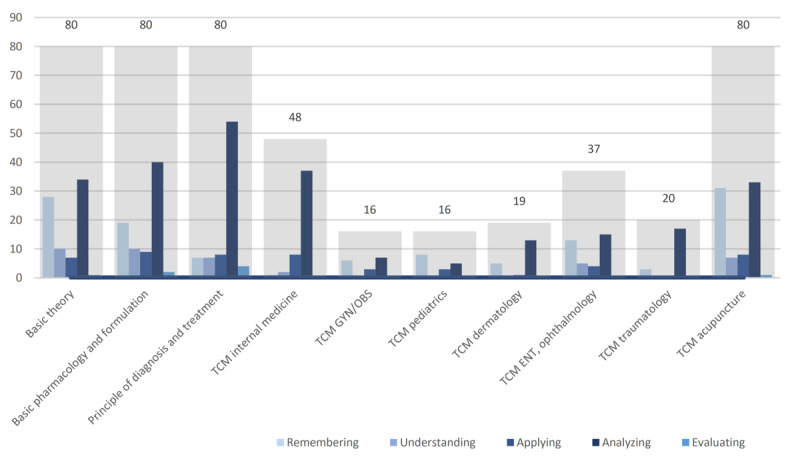
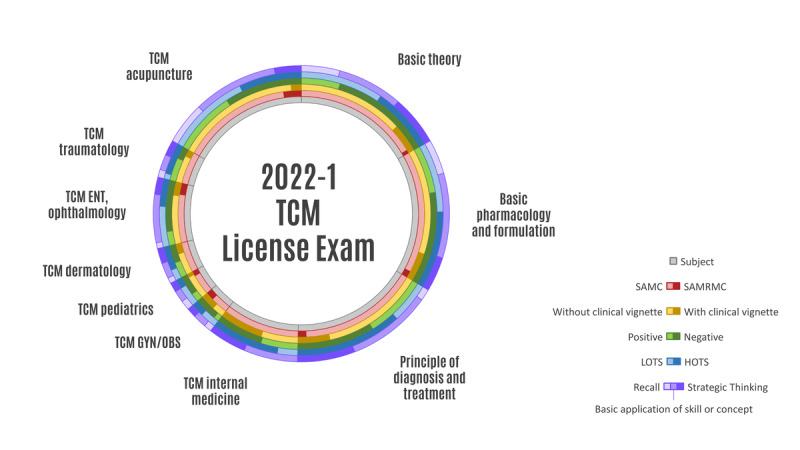
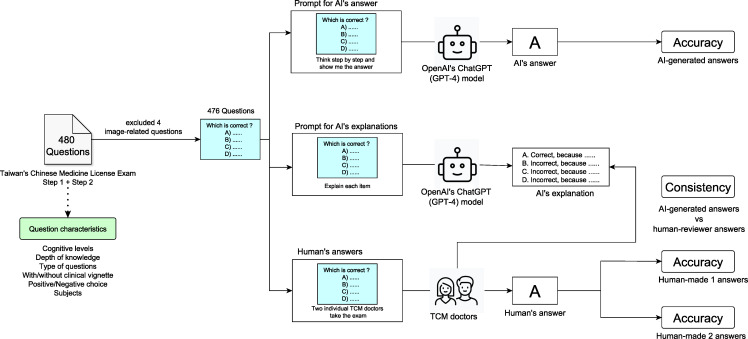
Methods: We used the GPT-4 model to respond to 480 questions from the 2022 TCM licensing examination. This study compared the performance of the model against that of licensed TCM doctors using 2 approaches, namely direct answer selection and provision of explanations before answer selection. The accuracy and consistency of AI-generated responses were analyzed. Moreover, a breakdown of question characteristics was performed based on the cognitive level, depth of knowledge, types of questions, vignette style, and polarity of questions.
Results: ChatGPT achieved an overall accuracy of 43.9%, which was lower than that of 2 human participants (70% and 78.4%). The analysis did not reveal a significant correlation between the accuracy of the model and the characteristics of the questions. An in-depth examination indicated that errors predominantly resulted from a misunderstanding of TCM concepts (55.3%), emphasizing the limitations of the model with regard to its TCM knowledge base and reasoning capability.
Conclusions: Although ChatGPT shows promise as an educational tool, its current performance on TCM licensing examinations is lacking. This highlights the need for enhancing AI models with specialized TCM training and suggests a cautious approach to utilizing AI for TCM education. Future research should focus on model improvement and the development of tailored educational applications to support TCM learning.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


