Comparison of ChatGPT-4, Copilot, Bard and Gemini Ultra on an Otolaryngology Question Bank
Abstract
Objective
To compare the performance of Google Bard, Microsoft Copilot, GPT-4 with vision (GPT-4) and Gemini Ultra on the OTO Chautauqua, a student-created, faculty-reviewed otolaryngology question bank.
Study Design
Comparative performance evaluation of different LLMs.
Setting
N/A.
Participants
N/A.
Methods
Large language models (LLMs) are being extensively tested in medical education. However, their accuracy and effectiveness remain understudied, particularly in otolaryngology. This study involved inputting 350 single-best-answer multiple choice questions, including 18 image-based questions, into four LLMS. Questions were sourced from six independent question banks related to (a) rhinology, (b) head and neck oncology, (c) endocrinology, (d) general otolaryngology, (e) paediatrics, (f) otology, (g) facial plastics, reconstruction and (h) trauma. LLMs were instructed to provide an output reasoning for their answers, the length of which was recorded.
Results
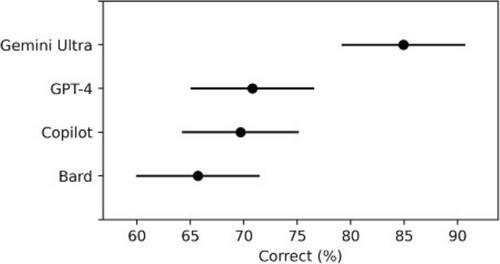
Aggregate and subgroup analysis revealed that Gemini (79.8%) outperformed the other LLMs, followed by GPT-4 (71.1%), Copilot (68.0%), and Bard (65.1%) in accuracy.
The LLMs had significantly different average response lengths, with Bard (x̄ = 1685.24) being the longest and no difference between GPT-4 (x̄ = 827.34) and Copilot (x̄ = 904.12). Gemini's longer responses (x̄ =1291.68) included explanatory images and links. Gemini and GPT-4 correctly answered image-based questions (n = 18), unlike Copilot and Bard, highlighting their adaptability and multimodal capabilities.
Conclusion
Gemini outperformed the other LLMs in terms of accuracy, followed by GPT-4, Copilot and Bard. GPT-4, although it has the second-highest accuracy, provides concise and relevant explanations. Despite the promising performance of LLMs, medical learners should cautiously assess accuracy and decision-making reliability.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


