Hyeji Lee, Wooheon Kim, Nahyeon Kwon, Chanhee Kim, Sungmin Kim, Joon-Yong An
{"title":"Lessons from national biobank projects utilizing whole-genome sequencing for population-scale genomics.","authors":"Hyeji Lee, Wooheon Kim, Nahyeon Kwon, Chanhee Kim, Sungmin Kim, Joon-Yong An","doi":"10.1186/s44342-025-00040-9","DOIUrl":null,"url":null,"abstract":"<p><p>Large-scale national biobank projects utilizing whole-genome sequencing have emerged as transformative resources for understanding human genetic variation and its relationship to health and disease. These initiatives, which include the UK Biobank, All of Us Research Program, Singapore's PRECISE, Biobank Japan, and the National Project of Bio-Big Data of Korea, are generating unprecedented volumes of high-resolution genomic data integrated with comprehensive phenotypic, environmental, and clinical information. This review examines the methodologies, contributions, and challenges of major WGS-based national genome projects worldwide. We first discuss the landscape of national biobank initiatives, highlighting their distinct approaches to data collection, participant recruitment, and phenotype characterization. We then introduce recent technological advances that enable efficient processing and analysis of large-scale WGS data, including improvements in variant calling algorithms, innovative methods for creating multi-sample VCFs, optimized data storage formats, and cloud-based computing solutions. The review synthesizes key discoveries from these projects, particularly in identifying expression quantitative trait loci and rare variants associated with complex diseases. Our review introduces the latest findings from the National Project of Bio-Big Data of Korea, which has advanced our understanding of population-specific genetic variation and rare diseases in Korean and East Asian populations. Finally, we discuss future directions and challenges in maximizing the impact of these resources on precision medicine and global health equity. This comprehensive examination demonstrates how large-scale national genome projects are revolutionizing genetic research and healthcare delivery while highlighting the importance of continued investment in diverse, population-specific genomic resources.</p>","PeriodicalId":94288,"journal":{"name":"Genomics & informatics","volume":"23 1","pages":"8"},"PeriodicalIF":0.0000,"publicationDate":"2025-03-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11887102/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Genomics & informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s44342-025-00040-9","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
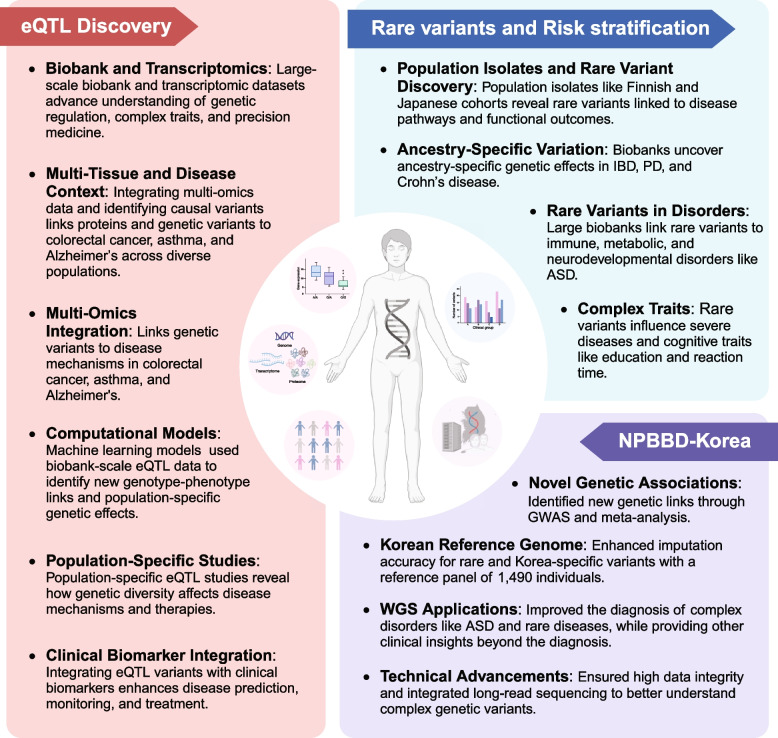
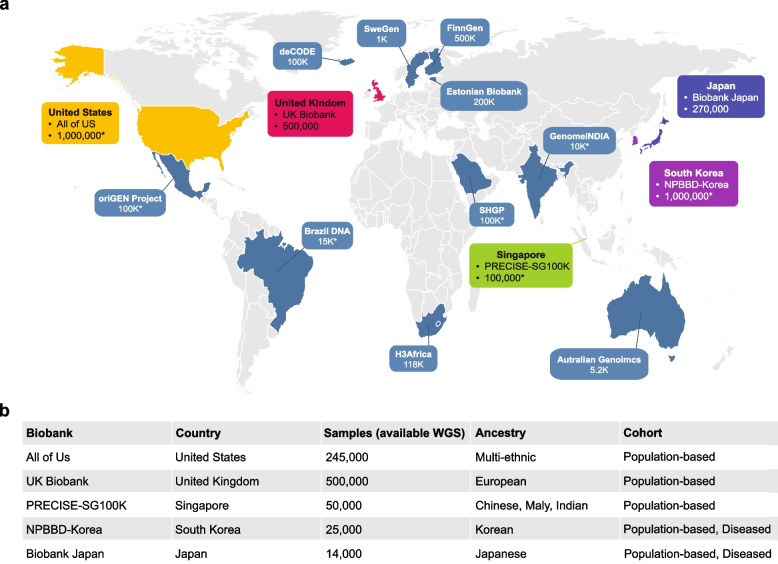
Large-scale national biobank projects utilizing whole-genome sequencing have emerged as transformative resources for understanding human genetic variation and its relationship to health and disease. These initiatives, which include the UK Biobank, All of Us Research Program, Singapore's PRECISE, Biobank Japan, and the National Project of Bio-Big Data of Korea, are generating unprecedented volumes of high-resolution genomic data integrated with comprehensive phenotypic, environmental, and clinical information. This review examines the methodologies, contributions, and challenges of major WGS-based national genome projects worldwide. We first discuss the landscape of national biobank initiatives, highlighting their distinct approaches to data collection, participant recruitment, and phenotype characterization. We then introduce recent technological advances that enable efficient processing and analysis of large-scale WGS data, including improvements in variant calling algorithms, innovative methods for creating multi-sample VCFs, optimized data storage formats, and cloud-based computing solutions. The review synthesizes key discoveries from these projects, particularly in identifying expression quantitative trait loci and rare variants associated with complex diseases. Our review introduces the latest findings from the National Project of Bio-Big Data of Korea, which has advanced our understanding of population-specific genetic variation and rare diseases in Korean and East Asian populations. Finally, we discuss future directions and challenges in maximizing the impact of these resources on precision medicine and global health equity. This comprehensive examination demonstrates how large-scale national genome projects are revolutionizing genetic research and healthcare delivery while highlighting the importance of continued investment in diverse, population-specific genomic resources.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


