Abubakar Ahmad Abdullahi, Murat Can Ganiz, Ural Koç, Muhammet Batuhan Gökhan, Ceren Aydın, Ali Bahadır Özdemir
{"title":"Deep learning for named entity recognition in Turkish radiology reports.","authors":"Abubakar Ahmad Abdullahi, Murat Can Ganiz, Ural Koç, Muhammet Batuhan Gökhan, Ceren Aydın, Ali Bahadır Özdemir","doi":"10.4274/dir.2025.243100","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>The primary objective of this research is to enhance the accuracy and efficiency of information extraction from radiology reports. In addressing this objective, the study aims to develop and evaluate a deep learning framework for named entity recognition (NER).</p><p><strong>Methods: </strong>We used a synthetic dataset of 1,056 Turkish radiology reports created and labeled by the radiologists in our research team. Due to privacy concerns, actual patient data could not be used; however, the synthetic reports closely mimic genuine reports in structure and content. We employed the four-stage DYGIE++ model for the experiments. First, we performed token encoding using four bidirectional encoder representations from transformers (BERT) models: BERTurk, BioBERTurk, PubMedBERT, and XLM-RoBERTa. Second, we introduced adaptive span enumeration, considering the word count of a sentence in Turkish. Third, we adopted span graph propagation to generate a multidirectional graph crucial for coreference resolution. Finally, we used a two-layered feed-forward neural network to classify the named entity.</p><p><strong>Results: </strong>The experiments conducted on the labeled dataset showcase the approach's effectiveness. The study achieved an F1 score of 80.1 for the NER task, with the BioBERTurk model, which is pre-trained on Turkish Wikipedia, radiology reports, and biomedical texts, proving to be the most effective of the four BERT models used in the experiment.</p><p><strong>Conclusion: </strong>We show how different dataset labels affect the model's performance. The results demonstrate the model's ability to handle the intricacies of Turkish radiology reports, providing a detailed analysis of precision, recall, and F1 scores for each label. Additionally, this study compares its findings with related research in other languages.</p><p><strong>Clinical significance: </strong>Our approach provides clinicians with more precise and comprehensive insights to improve patient care by extracting relevant information from radiology reports. This innovation in information extraction streamlines the diagnostic process and helps expedite patient treatment decisions.</p>","PeriodicalId":11341,"journal":{"name":"Diagnostic and interventional radiology","volume":" ","pages":"430-439"},"PeriodicalIF":1.7000,"publicationDate":"2025-09-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12417914/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Diagnostic and interventional radiology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.4274/dir.2025.243100","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/2/28 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
引用次数: 0
Abstract
Purpose: The primary objective of this research is to enhance the accuracy and efficiency of information extraction from radiology reports. In addressing this objective, the study aims to develop and evaluate a deep learning framework for named entity recognition (NER).
Methods: We used a synthetic dataset of 1,056 Turkish radiology reports created and labeled by the radiologists in our research team. Due to privacy concerns, actual patient data could not be used; however, the synthetic reports closely mimic genuine reports in structure and content. We employed the four-stage DYGIE++ model for the experiments. First, we performed token encoding using four bidirectional encoder representations from transformers (BERT) models: BERTurk, BioBERTurk, PubMedBERT, and XLM-RoBERTa. Second, we introduced adaptive span enumeration, considering the word count of a sentence in Turkish. Third, we adopted span graph propagation to generate a multidirectional graph crucial for coreference resolution. Finally, we used a two-layered feed-forward neural network to classify the named entity.
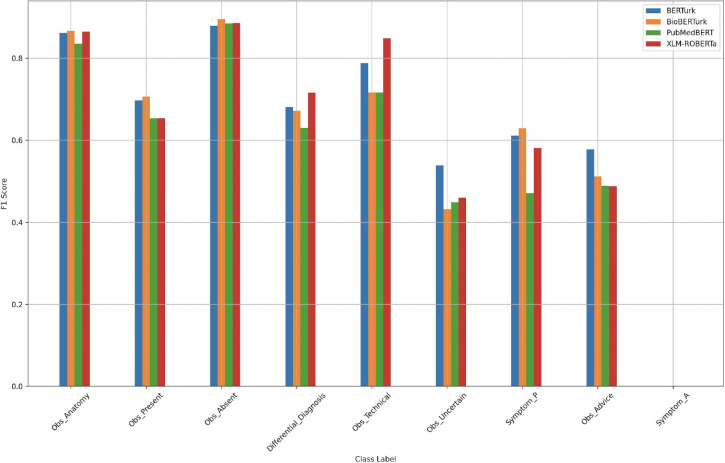
Results: The experiments conducted on the labeled dataset showcase the approach's effectiveness. The study achieved an F1 score of 80.1 for the NER task, with the BioBERTurk model, which is pre-trained on Turkish Wikipedia, radiology reports, and biomedical texts, proving to be the most effective of the four BERT models used in the experiment.
Conclusion: We show how different dataset labels affect the model's performance. The results demonstrate the model's ability to handle the intricacies of Turkish radiology reports, providing a detailed analysis of precision, recall, and F1 scores for each label. Additionally, this study compares its findings with related research in other languages.
Clinical significance: Our approach provides clinicians with more precise and comprehensive insights to improve patient care by extracting relevant information from radiology reports. This innovation in information extraction streamlines the diagnostic process and helps expedite patient treatment decisions.
期刊介绍:
Diagnostic and Interventional Radiology (Diagn Interv Radiol) is the open access, online-only official publication of Turkish Society of Radiology. It is published bimonthly and the journal’s publication language is English.
The journal is a medium for original articles, reviews, pictorial essays, technical notes related to all fields of diagnostic and interventional radiology.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


