Jaka Potočnik, Edel Thomas, Dearbhla Kearney, Ronan P Killeen, Eric J Heffernan, Shane J Foley
{"title":"Can ChatGPT and Gemini justify brain CT referrals? A comparative study with human experts and a custom prediction model.","authors":"Jaka Potočnik, Edel Thomas, Dearbhla Kearney, Ronan P Killeen, Eric J Heffernan, Shane J Foley","doi":"10.1186/s41747-025-00569-y","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The poor uptake of imaging referral guidelines in Europe results in a substantial amount of inappropriate computed tomography (CT) scans. Publicly available chatbots, ChatGPT and Gemini, offer an alternative for justifying real-world referrals. Recent research reports high ChatGPT accuracy when analysing American College of Radiology Appropriateness Criteria variants. We compared the chatbots' performance in interpreting, justifying, and suggesting alternative imaging for unstructured adult brain CT referrals in accordance with the European Society of Radiology iGuide. Our prediction model for automated iGuide categorisation of referrals was also compared against the chatbots.</p><p><strong>Methods: </strong>The iGuide justification of 143 real-world CT brain referrals, used to evaluate a prediction model, was analysed by two radiographers and radiologists. ChatGPT-4's and Gemini's imaging recommendations and pathology suspicions were compared with those of humans, with respect to referral completeness. Inter-rater reliability with κ statistics determined the agreement between entities.</p><p><strong>Results: </strong>Chatbots' performance was limited (κ = 0.3) but improved for more complete referrals. The prediction model outperformed the chatbots in justification analysis (κ = 0.853). The chatbots' interpretations of complete referrals were highly consistent (49/52, 94.2%). The agreement regarding alternative imaging was high for both complete and ambiguous referrals, with ChatGPT and Gemini correctly identifying imaging modality and anatomical region in 83/96 (86.5%) and 81/96 (84.4%) cases, respectively.</p><p><strong>Conclusion: </strong>The chatbots' ability to analyse the justification of adult brain CT referrals is limited to complete referrals, unlike our prediction model. Further research is needed to confirm these findings for other types of CT scans and modalities.</p><p><strong>Relevance statement: </strong>ChatGPT and Gemini exhibit potential in justifying free text brain CT referrals; however, further improvements are required to handle real-world referrals of varying quality.</p><p><strong>Key points: </strong>Custom prediction model's justification analysis strongly aligns with iGuide and surpasses chatbots. Chatbots incorrectly justified almost one-half of all CT brain referrals. Chatbots have limited performance in justifying ambiguous CT brain referrals. Chatbot performance improved when referrals were detailed and included suspected pathology.</p>","PeriodicalId":36926,"journal":{"name":"European Radiology Experimental","volume":"9 1","pages":"24"},"PeriodicalIF":3.6000,"publicationDate":"2025-02-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11836243/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"European Radiology Experimental","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s41747-025-00569-y","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The poor uptake of imaging referral guidelines in Europe results in a substantial amount of inappropriate computed tomography (CT) scans. Publicly available chatbots, ChatGPT and Gemini, offer an alternative for justifying real-world referrals. Recent research reports high ChatGPT accuracy when analysing American College of Radiology Appropriateness Criteria variants. We compared the chatbots' performance in interpreting, justifying, and suggesting alternative imaging for unstructured adult brain CT referrals in accordance with the European Society of Radiology iGuide. Our prediction model for automated iGuide categorisation of referrals was also compared against the chatbots.
Methods: The iGuide justification of 143 real-world CT brain referrals, used to evaluate a prediction model, was analysed by two radiographers and radiologists. ChatGPT-4's and Gemini's imaging recommendations and pathology suspicions were compared with those of humans, with respect to referral completeness. Inter-rater reliability with κ statistics determined the agreement between entities.
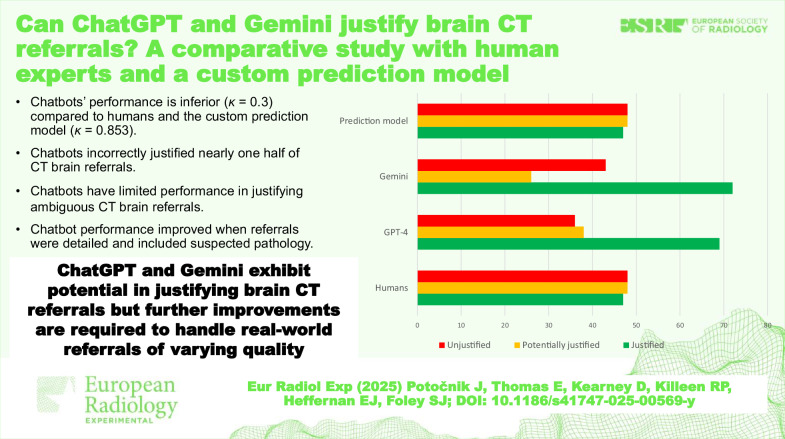
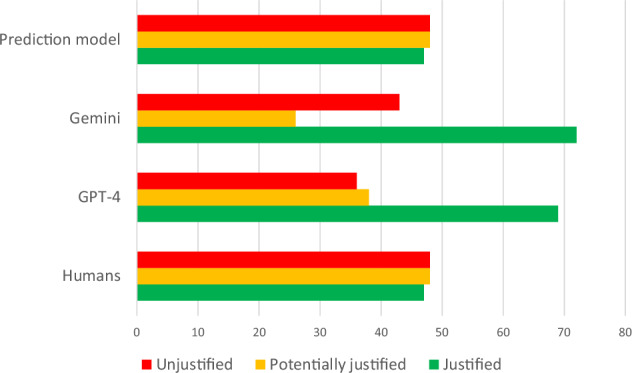
Results: Chatbots' performance was limited (κ = 0.3) but improved for more complete referrals. The prediction model outperformed the chatbots in justification analysis (κ = 0.853). The chatbots' interpretations of complete referrals were highly consistent (49/52, 94.2%). The agreement regarding alternative imaging was high for both complete and ambiguous referrals, with ChatGPT and Gemini correctly identifying imaging modality and anatomical region in 83/96 (86.5%) and 81/96 (84.4%) cases, respectively.
Conclusion: The chatbots' ability to analyse the justification of adult brain CT referrals is limited to complete referrals, unlike our prediction model. Further research is needed to confirm these findings for other types of CT scans and modalities.
Relevance statement: ChatGPT and Gemini exhibit potential in justifying free text brain CT referrals; however, further improvements are required to handle real-world referrals of varying quality.
Key points: Custom prediction model's justification analysis strongly aligns with iGuide and surpasses chatbots. Chatbots incorrectly justified almost one-half of all CT brain referrals. Chatbots have limited performance in justifying ambiguous CT brain referrals. Chatbot performance improved when referrals were detailed and included suspected pathology.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


