Rodrigo R Gameiro, Naira Link Woite, Christopher M Sauer, Sicheng Hao, Chrystinne Oliveira Fernandes, Anna E Premo, Alice Rangel Teixeira, Isabelle Resli, An-Kwok Ian Wong, Leo Anthony Celi
{"title":"The Data Artifacts Glossary: a community-based repository for bias on health datasets.","authors":"Rodrigo R Gameiro, Naira Link Woite, Christopher M Sauer, Sicheng Hao, Chrystinne Oliveira Fernandes, Anna E Premo, Alice Rangel Teixeira, Isabelle Resli, An-Kwok Ian Wong, Leo Anthony Celi","doi":"10.1186/s12929-024-01106-6","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The deployment of Artificial Intelligence (AI) in healthcare has the potential to transform patient care through improved diagnostics, personalized treatment plans, and more efficient resource management. However, the effectiveness and fairness of AI are critically dependent on the data it learns from. Biased datasets can lead to AI outputs that perpetuate disparities, particularly affecting social minorities and marginalized groups.</p><p><strong>Objective: </strong>This paper introduces the \"Data Artifacts Glossary\", a dynamic, open-source framework designed to systematically document and update potential biases in healthcare datasets. The aim is to provide a comprehensive tool that enhances the transparency and accuracy of AI applications in healthcare and contributes to understanding and addressing health inequities.</p><p><strong>Methods: </strong>Utilizing a methodology inspired by the Delphi method, a diverse team of experts conducted iterative rounds of discussions and literature reviews. The team synthesized insights to develop a comprehensive list of bias categories and designed the glossary's structure. The Data Artifacts Glossary was piloted using the MIMIC-IV dataset to validate its utility and structure.</p><p><strong>Results: </strong>The Data Artifacts Glossary adopts a collaborative approach modeled on successful open-source projects like Linux and Python. Hosted on GitHub, it utilizes robust version control and collaborative features, allowing stakeholders from diverse backgrounds to contribute. Through a rigorous peer review process managed by community members, the glossary ensures the continual refinement and accuracy of its contents. The implementation of the Data Artifacts Glossary with the MIMIC-IV dataset illustrates its utility. It categorizes biases, and facilitates their identification and understanding.</p><p><strong>Conclusion: </strong>The Data Artifacts Glossary serves as a vital resource for enhancing the integrity of AI applications in healthcare by providing a mechanism to recognize and mitigate dataset biases before they impact AI outputs. It not only aids in avoiding bias in model development but also contributes to understanding and addressing the root causes of health disparities.</p>","PeriodicalId":15365,"journal":{"name":"Journal of Biomedical Science","volume":"32 1","pages":"14"},"PeriodicalIF":12.1000,"publicationDate":"2025-02-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11792693/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Science","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s12929-024-01106-6","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CELL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The deployment of Artificial Intelligence (AI) in healthcare has the potential to transform patient care through improved diagnostics, personalized treatment plans, and more efficient resource management. However, the effectiveness and fairness of AI are critically dependent on the data it learns from. Biased datasets can lead to AI outputs that perpetuate disparities, particularly affecting social minorities and marginalized groups.
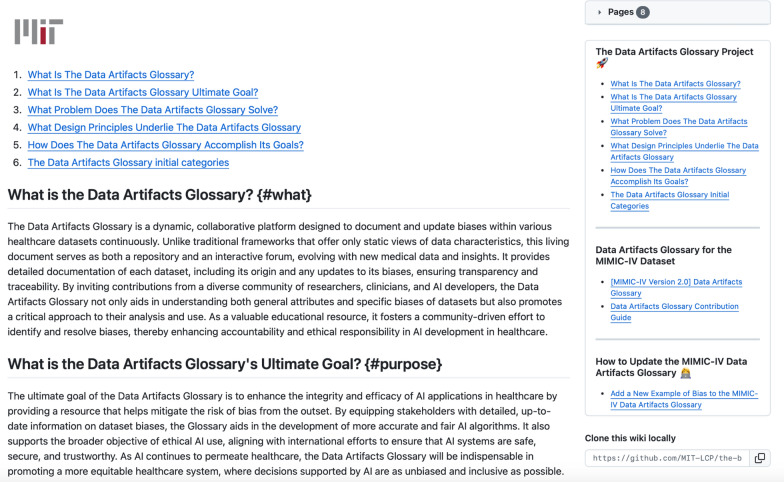
Objective: This paper introduces the "Data Artifacts Glossary", a dynamic, open-source framework designed to systematically document and update potential biases in healthcare datasets. The aim is to provide a comprehensive tool that enhances the transparency and accuracy of AI applications in healthcare and contributes to understanding and addressing health inequities.
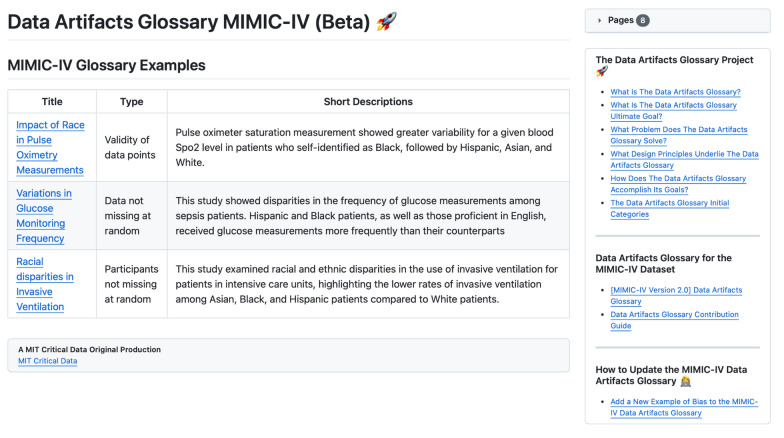
Methods: Utilizing a methodology inspired by the Delphi method, a diverse team of experts conducted iterative rounds of discussions and literature reviews. The team synthesized insights to develop a comprehensive list of bias categories and designed the glossary's structure. The Data Artifacts Glossary was piloted using the MIMIC-IV dataset to validate its utility and structure.
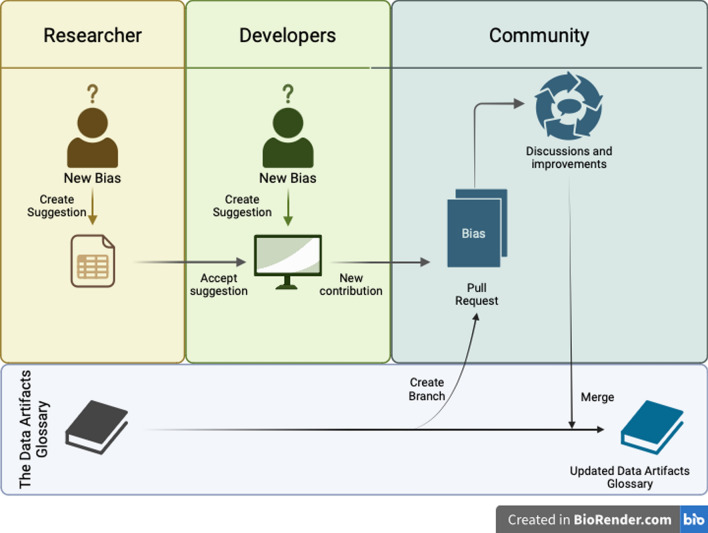
Results: The Data Artifacts Glossary adopts a collaborative approach modeled on successful open-source projects like Linux and Python. Hosted on GitHub, it utilizes robust version control and collaborative features, allowing stakeholders from diverse backgrounds to contribute. Through a rigorous peer review process managed by community members, the glossary ensures the continual refinement and accuracy of its contents. The implementation of the Data Artifacts Glossary with the MIMIC-IV dataset illustrates its utility. It categorizes biases, and facilitates their identification and understanding.
Conclusion: The Data Artifacts Glossary serves as a vital resource for enhancing the integrity of AI applications in healthcare by providing a mechanism to recognize and mitigate dataset biases before they impact AI outputs. It not only aids in avoiding bias in model development but also contributes to understanding and addressing the root causes of health disparities.
期刊介绍:
The Journal of Biomedical Science is an open access, peer-reviewed journal that focuses on fundamental and molecular aspects of basic medical sciences. It emphasizes molecular studies of biomedical problems and mechanisms. The National Science and Technology Council (NSTC), Taiwan supports the journal and covers the publication costs for accepted articles. The journal aims to provide an international platform for interdisciplinary discussions and contribute to the advancement of medicine. It benefits both readers and authors by accelerating the dissemination of research information and providing maximum access to scholarly communication. All articles published in the Journal of Biomedical Science are included in various databases such as Biological Abstracts, BIOSIS, CABI, CAS, Citebase, Current contents, DOAJ, Embase, EmBiology, and Global Health, among others.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


