{"title":"The advantages of lexicon-based sentiment analysis in an age of machine learning.","authors":"A Maurits van der Veen, Erik Bleich","doi":"10.1371/journal.pone.0313092","DOIUrl":null,"url":null,"abstract":"<p><p>Assessing whether texts are positive or negative-sentiment analysis-has wide-ranging applications across many disciplines. Automated approaches make it possible to code near unlimited quantities of texts rapidly, replicably, and with high accuracy. Compared to machine learning and large language model (LLM) approaches, lexicon-based methods may sacrifice some in performance, but in exchange they provide generalizability and domain independence, while crucially offering the possibility of identifying gradations in sentiment. We demonstrate the strong performance of lexica using MultiLexScaled, an approach which averages valences across a number of widely-used general-purpose lexica. We validate it against benchmark datasets from a range of different domains, comparing performance against machine learning and LLM alternatives. In addition, we illustrate the value of identifying fine-grained sentiment levels by showing, in an analysis of pre- and post-9/11 British press coverage of Muslims, that binarized valence metrics give rise to different (and erroneous) conclusions about the nature of the post-9/11 shock as well as about differences between broadsheet and tabloid coverage. The code to apply MultiLexScaled is available online.</p>","PeriodicalId":20189,"journal":{"name":"PLoS ONE","volume":"20 1","pages":"e0313092"},"PeriodicalIF":2.6000,"publicationDate":"2025-01-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11723603/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLoS ONE","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1371/journal.pone.0313092","RegionNum":3,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
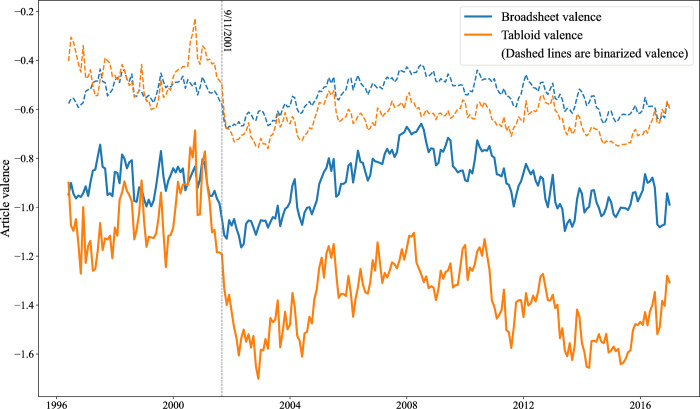
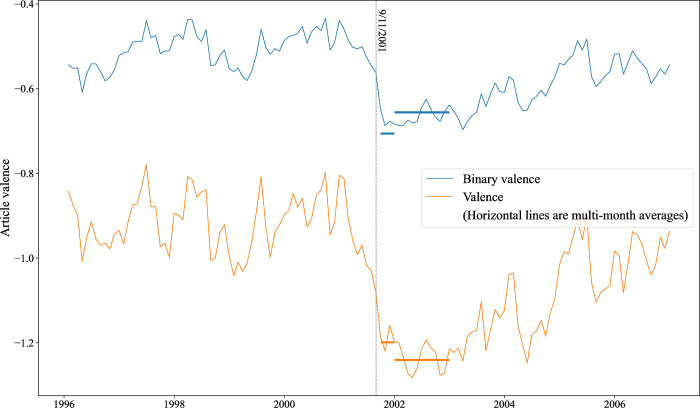
Assessing whether texts are positive or negative-sentiment analysis-has wide-ranging applications across many disciplines. Automated approaches make it possible to code near unlimited quantities of texts rapidly, replicably, and with high accuracy. Compared to machine learning and large language model (LLM) approaches, lexicon-based methods may sacrifice some in performance, but in exchange they provide generalizability and domain independence, while crucially offering the possibility of identifying gradations in sentiment. We demonstrate the strong performance of lexica using MultiLexScaled, an approach which averages valences across a number of widely-used general-purpose lexica. We validate it against benchmark datasets from a range of different domains, comparing performance against machine learning and LLM alternatives. In addition, we illustrate the value of identifying fine-grained sentiment levels by showing, in an analysis of pre- and post-9/11 British press coverage of Muslims, that binarized valence metrics give rise to different (and erroneous) conclusions about the nature of the post-9/11 shock as well as about differences between broadsheet and tabloid coverage. The code to apply MultiLexScaled is available online.
期刊介绍:
PLOS ONE is an international, peer-reviewed, open-access, online publication. PLOS ONE welcomes reports on primary research from any scientific discipline. It provides:
* Open-access—freely accessible online, authors retain copyright
* Fast publication times
* Peer review by expert, practicing researchers
* Post-publication tools to indicate quality and impact
* Community-based dialogue on articles
* Worldwide media coverage


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


