An evaluation framework for clinical use of large language models in patient interaction tasks
IF 58.7
1区 医学
Q1 BIOCHEMISTRY & MOLECULAR BIOLOGY
引用次数: 0
Abstract
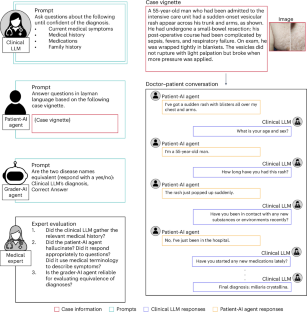
The integration of large language models (LLMs) into clinical diagnostics has the potential to transform doctor–patient interactions. However, the readiness of these models for real-world clinical application remains inadequately tested. This paper introduces the Conversational Reasoning Assessment Framework for Testing in Medicine (CRAFT-MD) approach for evaluating clinical LLMs. Unlike traditional methods that rely on structured medical examinations, CRAFT-MD focuses on natural dialogues, using simulated artificial intelligence agents to interact with LLMs in a controlled environment. We applied CRAFT-MD to assess the diagnostic capabilities of GPT-4, GPT-3.5, Mistral and LLaMA-2-7b across 12 medical specialties. Our experiments revealed critical insights into the limitations of current LLMs in terms of clinical conversational reasoning, history-taking and diagnostic accuracy. These limitations also persisted when analyzing multimodal conversational and visual assessment capabilities of GPT-4V. We propose a comprehensive set of recommendations for future evaluations of clinical LLMs based on our empirical findings. These recommendations emphasize realistic doctor–patient conversations, comprehensive history-taking, open-ended questioning and using a combination of automated and expert evaluations. The introduction of CRAFT-MD marks an advancement in testing of clinical LLMs, aiming to ensure that these models augment medical practice effectively and ethically. By simulating realistic doctor–patient conversations, a framework can be applied to large language models to investigate shortcomings and bias in patient interactions, providing insight before actual clinical deployment.

在患者交互任务中临床使用大型语言模型的评估框架
将大型语言模型(llm)集成到临床诊断中有可能改变医患互动。然而,这些模型对实际临床应用的准备程度仍然没有得到充分的测试。本文介绍了用于评估临床法学硕士的医学测试会话推理评估框架(CRAFT-MD)方法。与依赖结构化医学检查的传统方法不同,CRAFT-MD侧重于自然对话,在受控环境中使用模拟人工智能代理与法学硕士进行交互。我们应用CRAFT-MD评估了GPT-4、GPT-3.5、Mistral和LLaMA-2-7b在12个医学专业中的诊断能力。我们的实验揭示了当前法学硕士在临床会话推理、历史记录和诊断准确性方面的局限性。在分析GPT-4V的多模态会话和视觉评估能力时,这些局限性也存在。根据我们的实证研究结果,我们为临床法学硕士的未来评估提出了一套全面的建议。这些建议强调现实的医患对话、全面的病史记录、开放式的提问以及自动化和专家评估的结合。CRAFT-MD的引入标志着临床法学硕士测试的进步,旨在确保这些模型有效地和合乎道德地增加医疗实践。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Nature Medicine
医学-生化与分子生物学
CiteScore
100.90
自引率
0.70%
发文量
525
审稿时长
1 months
期刊介绍:
Nature Medicine is a monthly journal publishing original peer-reviewed research in all areas of medicine. The publication focuses on originality, timeliness, interdisciplinary interest, and the impact on improving human health. In addition to research articles, Nature Medicine also publishes commissioned content such as News, Reviews, and Perspectives. This content aims to provide context for the latest advances in translational and clinical research, reaching a wide audience of M.D. and Ph.D. readers. All editorial decisions for the journal are made by a team of full-time professional editors.
Nature Medicine consider all types of clinical research, including:
-Case-reports and small case series
-Clinical trials, whether phase 1, 2, 3 or 4
-Observational studies
-Meta-analyses
-Biomarker studies
-Public and global health studies
Nature Medicine is also committed to facilitating communication between translational and clinical researchers. As such, we consider “hybrid” studies with preclinical and translational findings reported alongside data from clinical studies.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


