Wee Shin Lim, Shu-I Chiu, Pei-Ling Peng, Jyh-Shing Roger Jang, Sol-Hee Lee, Chin-Hsien Lin, Han-Joon Kim
{"title":"A cross-language speech model for detection of Parkinson's disease.","authors":"Wee Shin Lim, Shu-I Chiu, Pei-Ling Peng, Jyh-Shing Roger Jang, Sol-Hee Lee, Chin-Hsien Lin, Han-Joon Kim","doi":"10.1007/s00702-024-02874-z","DOIUrl":null,"url":null,"abstract":"<p><p>Speech change is a biometric marker for Parkinson's disease (PD). However, evaluating speech variability across diverse languages is challenging. We aimed to develop a cross-language algorithm differentiating between PD patients and healthy controls using a Taiwanese and Korean speech data set. We recruited 299 healthy controls and 347 patients with PD from Taiwan and Korea. Participants with PD underwent smartphone-based speech recordings during the \"on\" phase. Each Korean participant performed various speech texts, while the Taiwanese participant read a standardized, fixed-length article. Korean short-speech (≦15 syllables) and long-speech (> 15 syllables) recordings were combined with the Taiwanese speech dataset. The merged dataset was split into a training set (controls vs. early-stage PD) and a validation set (controls vs. advanced-stage PD) to evaluate the model's effectiveness in differentiating PD patients from controls across languages based on speech length. Numerous acoustic and linguistic speech features were extracted and combined with machine learning algorithms to distinguish PD patients from controls. The area under the receiver operating characteristic (AUROC) curve was calculated to assess diagnostic performance. Random forest and AdaBoost classifiers showed an AUROC 0.82 for distinguishing patients with early-stage PD from controls. In the validation cohort, the random forest algorithm maintained this value (0.90) for discriminating advanced-stage PD patients. The model showed superior performance in the combined language cohort (AUROC 0.90) than either the Korean (AUROC 0.87) or Taiwanese (AUROC 0.88) cohorts individually. However, with another merged speech data set of short-speech recordings < 25 characters, the diagnostic performance to identify early-stage PD patients from controls dropped to 0.72 and showed a further limited ability to discriminate advanced-stage patients. Leveraging multifaceted speech features, including both acoustic and linguistic characteristics, could aid in distinguishing PD patients from healthy individuals, even across different languages.</p>","PeriodicalId":16579,"journal":{"name":"Journal of Neural Transmission","volume":" ","pages":"579-590"},"PeriodicalIF":4.0000,"publicationDate":"2025-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11909049/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Neural Transmission","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s00702-024-02874-z","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/12/30 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"CLINICAL NEUROLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
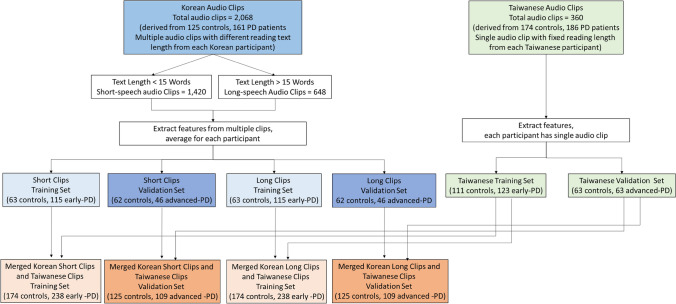
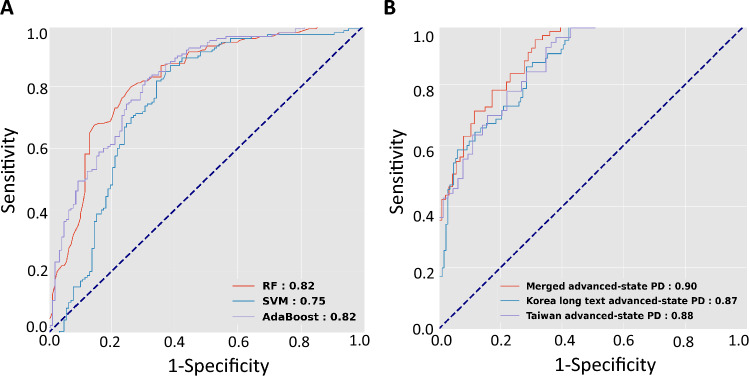
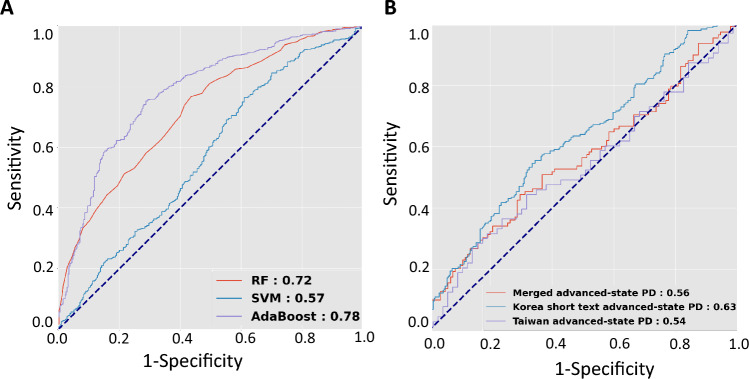
Speech change is a biometric marker for Parkinson's disease (PD). However, evaluating speech variability across diverse languages is challenging. We aimed to develop a cross-language algorithm differentiating between PD patients and healthy controls using a Taiwanese and Korean speech data set. We recruited 299 healthy controls and 347 patients with PD from Taiwan and Korea. Participants with PD underwent smartphone-based speech recordings during the "on" phase. Each Korean participant performed various speech texts, while the Taiwanese participant read a standardized, fixed-length article. Korean short-speech (≦15 syllables) and long-speech (> 15 syllables) recordings were combined with the Taiwanese speech dataset. The merged dataset was split into a training set (controls vs. early-stage PD) and a validation set (controls vs. advanced-stage PD) to evaluate the model's effectiveness in differentiating PD patients from controls across languages based on speech length. Numerous acoustic and linguistic speech features were extracted and combined with machine learning algorithms to distinguish PD patients from controls. The area under the receiver operating characteristic (AUROC) curve was calculated to assess diagnostic performance. Random forest and AdaBoost classifiers showed an AUROC 0.82 for distinguishing patients with early-stage PD from controls. In the validation cohort, the random forest algorithm maintained this value (0.90) for discriminating advanced-stage PD patients. The model showed superior performance in the combined language cohort (AUROC 0.90) than either the Korean (AUROC 0.87) or Taiwanese (AUROC 0.88) cohorts individually. However, with another merged speech data set of short-speech recordings < 25 characters, the diagnostic performance to identify early-stage PD patients from controls dropped to 0.72 and showed a further limited ability to discriminate advanced-stage patients. Leveraging multifaceted speech features, including both acoustic and linguistic characteristics, could aid in distinguishing PD patients from healthy individuals, even across different languages.
期刊介绍:
The investigation of basic mechanisms involved in the pathogenesis of neurological and psychiatric disorders has undoubtedly deepened our knowledge of these types of disorders. The impact of basic neurosciences on the understanding of the pathophysiology of the brain will further increase due to important developments such as the emergence of more specific psychoactive compounds and new technologies.
The Journal of Neural Transmission aims to establish an interface between basic sciences and clinical neurology and psychiatry. It intends to put a special emphasis on translational publications of the newest developments in the field from all disciplines of the neural sciences that relate to a better understanding and treatment of neurological and psychiatric disorders.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


