{"title":"QM40, Realistic Quantum Mechanical Dataset for Machine Learning in Molecular Science.","authors":"Ayesh Madushanka, Renaldo T Moura, Elfi Kraka","doi":"10.1038/s41597-024-04206-y","DOIUrl":null,"url":null,"abstract":"<p><p>The growing popularity of machine learning (ML) and deep learning (DL) in scientific fields is hindered by the scarcity of high-quality datasets. While quantum mechanical (QM) predictions using DL techniques such as graph neural networks (GNNs) and generative models are gaining traction, insufficient training data remains a bottleneck. The QM40 dataset addresses this challenge by representing 88% of the FDA-approved drug chemical space. It includes molecules containing 10 to 40 atoms and composed of elements commonly found in drug molecular structures (C, O, N, S, F, Cl). QM40 offers valuable resources for researchers which include the core QM40 main dataset, containing 16 key quantum mechanical parameters for 162,954 molecules calculated using the B3LYP/6-31G(2df,p) level of theory in Gaussian16, ensuring consistency with established datasets like QM9 and Alchemy. This compatibility allows for future concatenation of QM40 with these datasets. In addition to other valuable information, the QM40 dataset offers the initial and optimized Cartesian coordinates, Mulliken charges, and detailed bond information, including local vibrational mode force constants, which serve as indicators of bond strength. QM40 can be used to benchmark both existing and new methods for predicting QM calculations using ML and DL techniques.</p>","PeriodicalId":21597,"journal":{"name":"Scientific Data","volume":"11 1","pages":"1376"},"PeriodicalIF":6.9000,"publicationDate":"2024-12-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11655646/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Scientific Data","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41597-024-04206-y","RegionNum":2,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
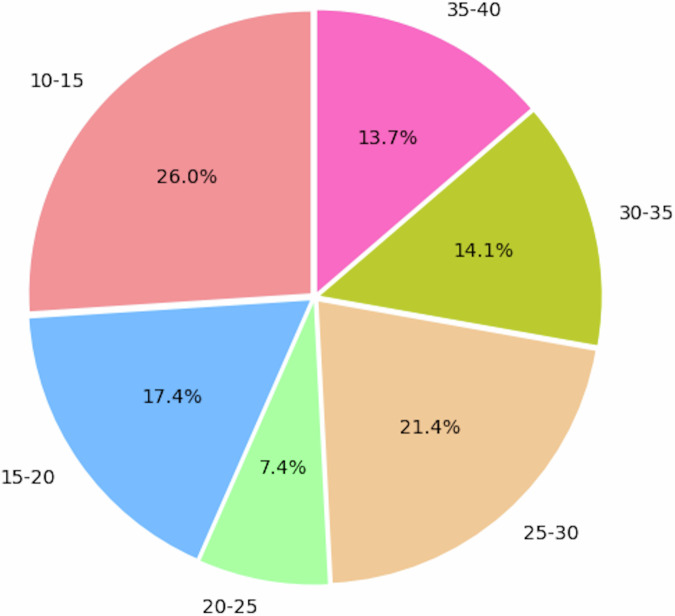
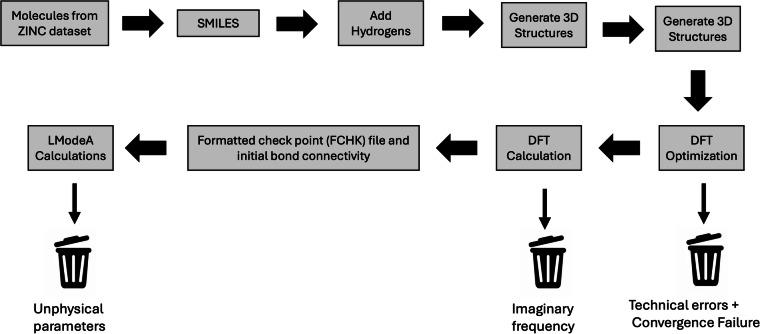
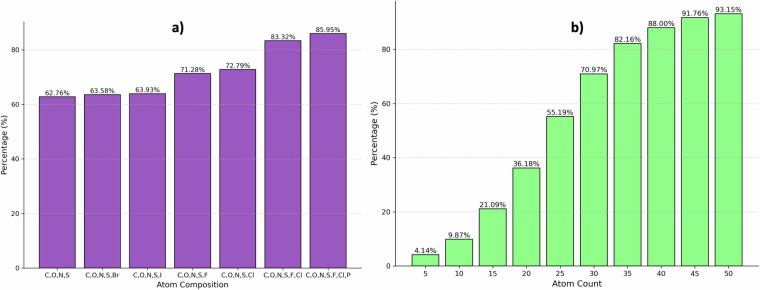
The growing popularity of machine learning (ML) and deep learning (DL) in scientific fields is hindered by the scarcity of high-quality datasets. While quantum mechanical (QM) predictions using DL techniques such as graph neural networks (GNNs) and generative models are gaining traction, insufficient training data remains a bottleneck. The QM40 dataset addresses this challenge by representing 88% of the FDA-approved drug chemical space. It includes molecules containing 10 to 40 atoms and composed of elements commonly found in drug molecular structures (C, O, N, S, F, Cl). QM40 offers valuable resources for researchers which include the core QM40 main dataset, containing 16 key quantum mechanical parameters for 162,954 molecules calculated using the B3LYP/6-31G(2df,p) level of theory in Gaussian16, ensuring consistency with established datasets like QM9 and Alchemy. This compatibility allows for future concatenation of QM40 with these datasets. In addition to other valuable information, the QM40 dataset offers the initial and optimized Cartesian coordinates, Mulliken charges, and detailed bond information, including local vibrational mode force constants, which serve as indicators of bond strength. QM40 can be used to benchmark both existing and new methods for predicting QM calculations using ML and DL techniques.
期刊介绍:
Scientific Data is an open-access journal focused on data, publishing descriptions of research datasets and articles on data sharing across natural sciences, medicine, engineering, and social sciences. Its goal is to enhance the sharing and reuse of scientific data, encourage broader data sharing, and acknowledge those who share their data.
The journal primarily publishes Data Descriptors, which offer detailed descriptions of research datasets, including data collection methods and technical analyses validating data quality. These descriptors aim to facilitate data reuse rather than testing hypotheses or presenting new interpretations, methods, or in-depth analyses.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


