Omri Raccah, Phoebe Chen, Todd M Gureckis, David Poeppel, Vy A Vo
{"title":"The \"Naturalistic Free Recall\" dataset: four stories, hundreds of participants, and high-fidelity transcriptions.","authors":"Omri Raccah, Phoebe Chen, Todd M Gureckis, David Poeppel, Vy A Vo","doi":"10.1038/s41597-024-04082-6","DOIUrl":null,"url":null,"abstract":"<p><p>The \"Naturalistic Free Recall\" dataset provides transcribed verbal recollections of four spoken narratives collected from 229 participants. Each participant listened to two stories, varying in duration from approximately 8 to 13 minutes, recorded by different speakers. Subsequently, participants were tasked with verbally recalling the narrative content in as much detail as possible and in the correct order. The dataset includes high-fidelity, time-stamped text transcripts of both the original narratives and participants' recollections. To validate the dataset, we apply a previously published automated method to score memory performance for narrative content. Using this approach, we extend effects traditionally observed in classic list-learning paradigms. The analysis of narrative contents and its verbal recollection presents unique challenges compared to controlled list-learning experiments. To facilitate the use of these rich data by the community, we offer an overview of recent computational methods that can be used to annotate and evaluate key properties of narratives and their recollections. Using advancements in machine learning and natural language processing, these methods can help the community understand the role of event structure, discourse properties, prediction error, high-level semantic features (e.g., idioms, humor), and more. All experimental materials, code, and data are publicly available to facilitate new advances in understanding human memory.</p>","PeriodicalId":21597,"journal":{"name":"Scientific Data","volume":"11 1","pages":"1317"},"PeriodicalIF":6.9000,"publicationDate":"2024-12-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11615391/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Scientific Data","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41597-024-04082-6","RegionNum":2,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
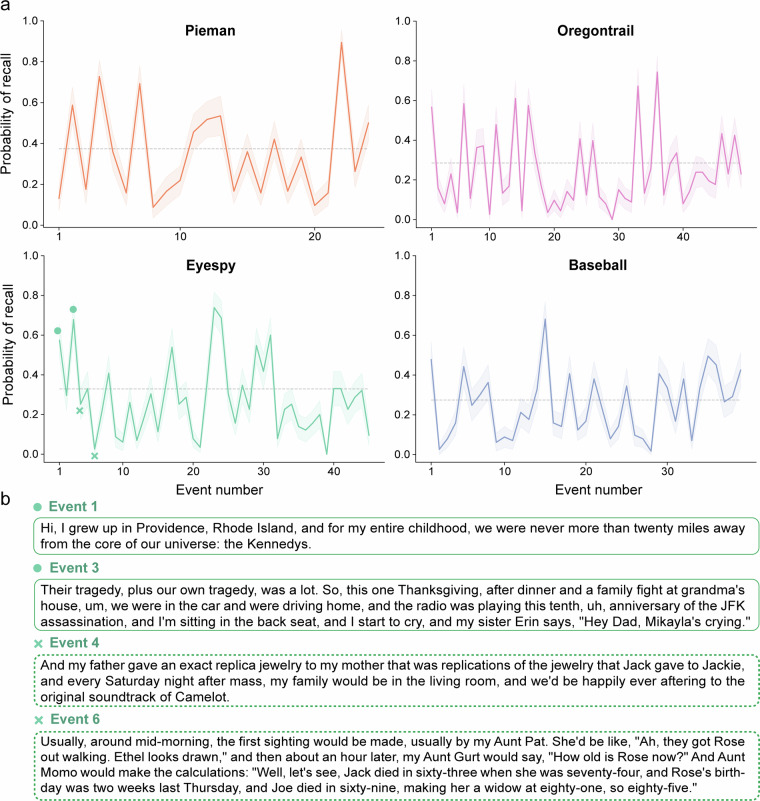
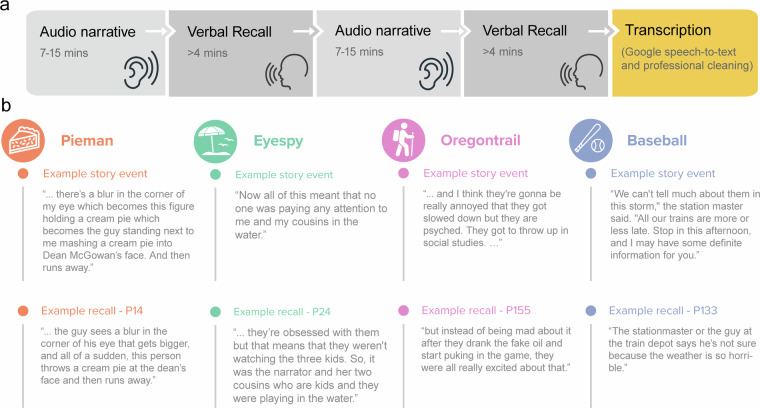
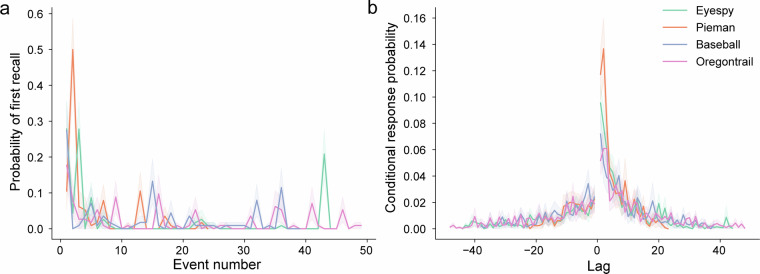
The "Naturalistic Free Recall" dataset provides transcribed verbal recollections of four spoken narratives collected from 229 participants. Each participant listened to two stories, varying in duration from approximately 8 to 13 minutes, recorded by different speakers. Subsequently, participants were tasked with verbally recalling the narrative content in as much detail as possible and in the correct order. The dataset includes high-fidelity, time-stamped text transcripts of both the original narratives and participants' recollections. To validate the dataset, we apply a previously published automated method to score memory performance for narrative content. Using this approach, we extend effects traditionally observed in classic list-learning paradigms. The analysis of narrative contents and its verbal recollection presents unique challenges compared to controlled list-learning experiments. To facilitate the use of these rich data by the community, we offer an overview of recent computational methods that can be used to annotate and evaluate key properties of narratives and their recollections. Using advancements in machine learning and natural language processing, these methods can help the community understand the role of event structure, discourse properties, prediction error, high-level semantic features (e.g., idioms, humor), and more. All experimental materials, code, and data are publicly available to facilitate new advances in understanding human memory.
期刊介绍:
Scientific Data is an open-access journal focused on data, publishing descriptions of research datasets and articles on data sharing across natural sciences, medicine, engineering, and social sciences. Its goal is to enhance the sharing and reuse of scientific data, encourage broader data sharing, and acknowledge those who share their data.
The journal primarily publishes Data Descriptors, which offer detailed descriptions of research datasets, including data collection methods and technical analyses validating data quality. These descriptors aim to facilitate data reuse rather than testing hypotheses or presenting new interpretations, methods, or in-depth analyses.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


