Eric Chalmers, Santina Duarte, Xena Al-Hejji, Daniel Devoe, Aaron Gruber, Robert J McDonald
{"title":"Simulated synapse loss induces depression-like behaviors in deep reinforcement learning.","authors":"Eric Chalmers, Santina Duarte, Xena Al-Hejji, Daniel Devoe, Aaron Gruber, Robert J McDonald","doi":"10.3389/fncom.2024.1466364","DOIUrl":null,"url":null,"abstract":"<p><p>Deep Reinforcement Learning is a branch of artificial intelligence that uses artificial neural networks to model reward-based learning as it occurs in biological agents. Here we modify a Deep Reinforcement Learning approach by imposing a suppressive effect on the connections between neurons in the artificial network-simulating the effect of dendritic spine loss as observed in major depressive disorder (MDD). Surprisingly, this simulated spine loss is sufficient to induce a variety of MDD-like behaviors in the artificially intelligent agent, including anhedonia, increased temporal discounting, avoidance, and an altered exploration/exploitation balance. Furthermore, simulating alternative and longstanding reward-processing-centric conceptions of MDD (dysfunction of the dopamine system, altered reward discounting, context-dependent learning rates, increased exploration) does not produce the same range of MDD-like behaviors. These results support a conceptual model of MDD as a reduction of brain connectivity (and thus information-processing capacity) rather than an imbalance in monoamines-though the computational model suggests a possible explanation for the dysfunction of dopamine systems in MDD. Reversing the spine-loss effect in our computational MDD model can lead to rescue of rewarding behavior under some conditions. This supports the search for treatments that increase plasticity and synaptogenesis, and the model suggests some implications for their effective administration.</p>","PeriodicalId":12363,"journal":{"name":"Frontiers in Computational Neuroscience","volume":"18 ","pages":"1466364"},"PeriodicalIF":2.3000,"publicationDate":"2024-11-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11576168/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Computational Neuroscience","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3389/fncom.2024.1466364","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
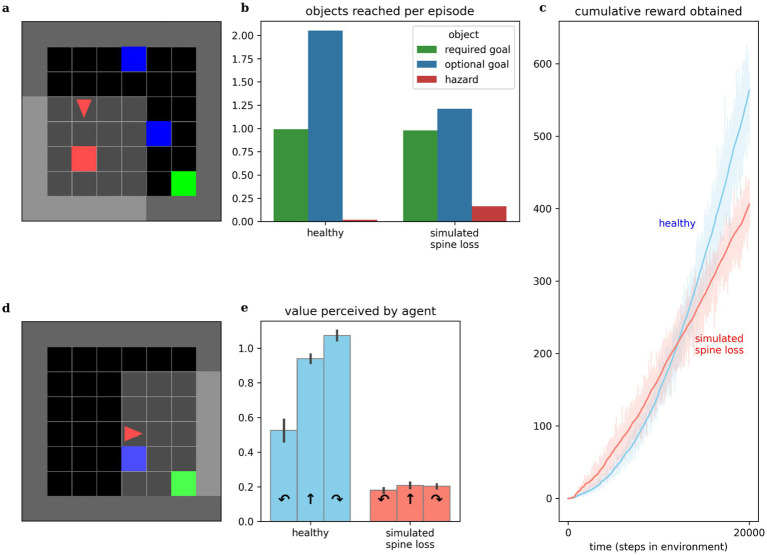
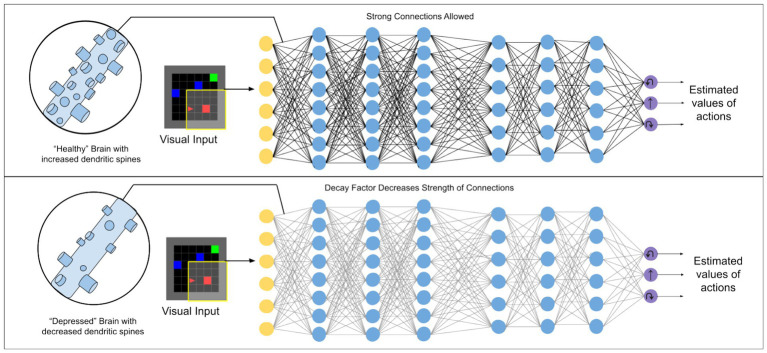
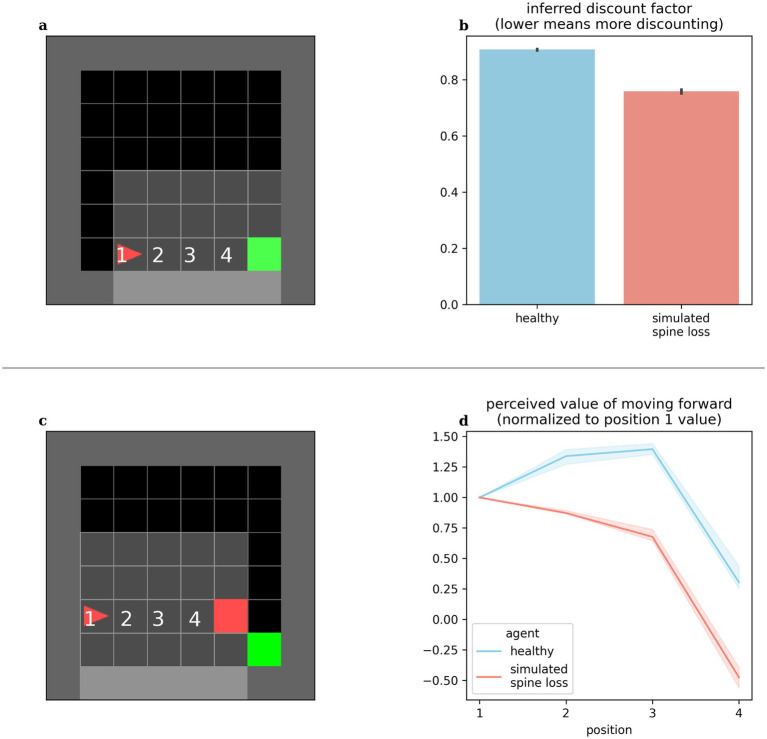
Deep Reinforcement Learning is a branch of artificial intelligence that uses artificial neural networks to model reward-based learning as it occurs in biological agents. Here we modify a Deep Reinforcement Learning approach by imposing a suppressive effect on the connections between neurons in the artificial network-simulating the effect of dendritic spine loss as observed in major depressive disorder (MDD). Surprisingly, this simulated spine loss is sufficient to induce a variety of MDD-like behaviors in the artificially intelligent agent, including anhedonia, increased temporal discounting, avoidance, and an altered exploration/exploitation balance. Furthermore, simulating alternative and longstanding reward-processing-centric conceptions of MDD (dysfunction of the dopamine system, altered reward discounting, context-dependent learning rates, increased exploration) does not produce the same range of MDD-like behaviors. These results support a conceptual model of MDD as a reduction of brain connectivity (and thus information-processing capacity) rather than an imbalance in monoamines-though the computational model suggests a possible explanation for the dysfunction of dopamine systems in MDD. Reversing the spine-loss effect in our computational MDD model can lead to rescue of rewarding behavior under some conditions. This supports the search for treatments that increase plasticity and synaptogenesis, and the model suggests some implications for their effective administration.
期刊介绍:
Frontiers in Computational Neuroscience is a first-tier electronic journal devoted to promoting theoretical modeling of brain function and fostering interdisciplinary interactions between theoretical and experimental neuroscience. Progress in understanding the amazing capabilities of the brain is still limited, and we believe that it will only come with deep theoretical thinking and mutually stimulating cooperation between different disciplines and approaches. We therefore invite original contributions on a wide range of topics that present the fruits of such cooperation, or provide stimuli for future alliances. We aim to provide an interactive forum for cutting-edge theoretical studies of the nervous system, and for promulgating the best theoretical research to the broader neuroscience community. Models of all styles and at all levels are welcome, from biophysically motivated realistic simulations of neurons and synapses to high-level abstract models of inference and decision making. While the journal is primarily focused on theoretically based and driven research, we welcome experimental studies that validate and test theoretical conclusions.
Also: comp neuro
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


