Ali Akbar Khan, Muhammad Salman Bashir, Asma Batool, Muhammad Summair Raza, Muhammad Adnan Bashir
{"title":"K-Means Centroids Initialization Based on Differentiation Between Instances Attributes","authors":"Ali Akbar Khan, Muhammad Salman Bashir, Asma Batool, Muhammad Summair Raza, Muhammad Adnan Bashir","doi":"10.1155/2024/7086878","DOIUrl":null,"url":null,"abstract":"<div>\n <p>The conventional K-Means clustering algorithm is widely used for grouping similar data points by initially selecting random centroids. However, the accuracy of clustering results is significantly influenced by the initial centroid selection. Despite different approaches, including various K-Means versions, suboptimal outcomes persist due to inadequate initial centroid choices and reliance on common normalization techniques like min-max normalization. In this study, we propose an improved algorithm that selects initial centroids more effectively by utilizing a novel formula to differentiate between instance attributes, creating a single weight for differentiation. We introduce a preprocessing phase for dataset normalization without forcing values into a specific range, yielding significantly improved results compared to unnormalized datasets and those normalized using min-max techniques. For our experiments, we used five real datasets and five simulated datasets. The proposed algorithm is evaluated using various metrics and an external benchmark measure, such as the Adjusted Rand Index (ARI), and compared with the traditional K-Means algorithm and 11 other modified K-Means algorithms. Experimental evaluations on these datasets demonstrate the superiority of our proposed methodologies, achieving an impressive average accuracy rate of up to 95.47% and an average ARI score of 0.95. Additionally, the number of iterations required is reduced compared to the conventional K-Means algorithm. By introducing innovative techniques, this research provides significant contributions to the field of data clustering, particularly in addressing modern data-driven clustering challenges.</p>\n </div>","PeriodicalId":14089,"journal":{"name":"International Journal of Intelligent Systems","volume":"2024 1","pages":""},"PeriodicalIF":5.0000,"publicationDate":"2024-11-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1155/2024/7086878","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Intelligent Systems","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1155/2024/7086878","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
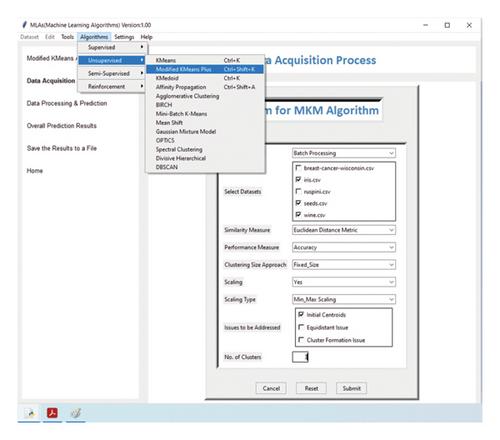
The conventional K-Means clustering algorithm is widely used for grouping similar data points by initially selecting random centroids. However, the accuracy of clustering results is significantly influenced by the initial centroid selection. Despite different approaches, including various K-Means versions, suboptimal outcomes persist due to inadequate initial centroid choices and reliance on common normalization techniques like min-max normalization. In this study, we propose an improved algorithm that selects initial centroids more effectively by utilizing a novel formula to differentiate between instance attributes, creating a single weight for differentiation. We introduce a preprocessing phase for dataset normalization without forcing values into a specific range, yielding significantly improved results compared to unnormalized datasets and those normalized using min-max techniques. For our experiments, we used five real datasets and five simulated datasets. The proposed algorithm is evaluated using various metrics and an external benchmark measure, such as the Adjusted Rand Index (ARI), and compared with the traditional K-Means algorithm and 11 other modified K-Means algorithms. Experimental evaluations on these datasets demonstrate the superiority of our proposed methodologies, achieving an impressive average accuracy rate of up to 95.47% and an average ARI score of 0.95. Additionally, the number of iterations required is reduced compared to the conventional K-Means algorithm. By introducing innovative techniques, this research provides significant contributions to the field of data clustering, particularly in addressing modern data-driven clustering challenges.
期刊介绍:
The International Journal of Intelligent Systems serves as a forum for individuals interested in tapping into the vast theories based on intelligent systems construction. With its peer-reviewed format, the journal explores several fascinating editorials written by today''s experts in the field. Because new developments are being introduced each day, there''s much to be learned — examination, analysis creation, information retrieval, man–computer interactions, and more. The International Journal of Intelligent Systems uses charts and illustrations to demonstrate these ground-breaking issues, and encourages readers to share their thoughts and experiences.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


