Dong Chen, Peisong Wu, Mingdong Chen, Mengtao Wu, Tao Zhang, Chuanqi Li
{"title":"LS-VIT: Vision Transformer for action recognition based on long and short-term temporal difference.","authors":"Dong Chen, Peisong Wu, Mingdong Chen, Mengtao Wu, Tao Zhang, Chuanqi Li","doi":"10.3389/fnbot.2024.1457843","DOIUrl":null,"url":null,"abstract":"<p><p>Over the past few years, a growing number of researchers have dedicated their efforts to focusing on temporal modeling. The advent of transformer-based methods has notably advanced the field of 2D image-based vision tasks. However, with respect to 3D video tasks such as action recognition, applying temporal transformations directly to video data significantly increases both computational and memory demands. This surge in resource consumption is due to the multiplication of data patches and the added complexity of self-aware computations. Accordingly, building efficient and precise 3D self-attentive models for video content represents as a major challenge for transformers. In our research, we introduce an Long and Short-term Temporal Difference Vision Transformer (LS-VIT). This method incorporates short-term motion details into images by weighting the difference across several consecutive frames, thereby equipping the original image with the ability to model short-term motions. Concurrently, we integrate a module designed to understand long-term motion details. This module enhances the model's capacity for long-term motion modeling by directly integrating temporal differences from various segments via motion excitation. Our thorough analysis confirms that the LS-VIT achieves high recognition accuracy across multiple benchmarks (e.g., UCF101, HMDB51, Kinetics-400). These research results indicate that LS-VIT has the potential for further optimization, which can improve real-time performance and action prediction capabilities.</p>","PeriodicalId":12628,"journal":{"name":"Frontiers in Neurorobotics","volume":"18 ","pages":"1457843"},"PeriodicalIF":2.8000,"publicationDate":"2024-10-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11560894/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Neurorobotics","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.3389/fnbot.2024.1457843","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
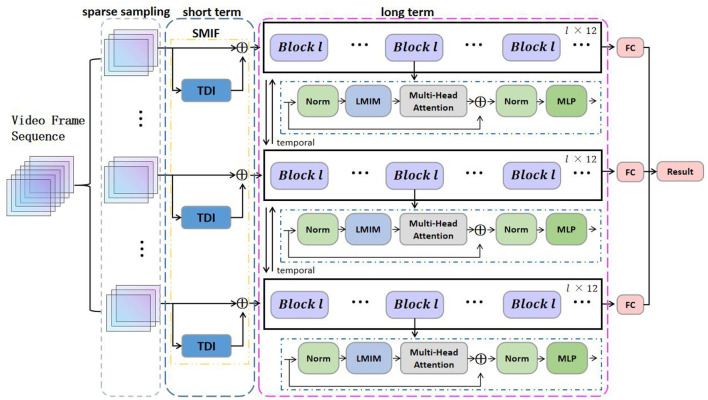
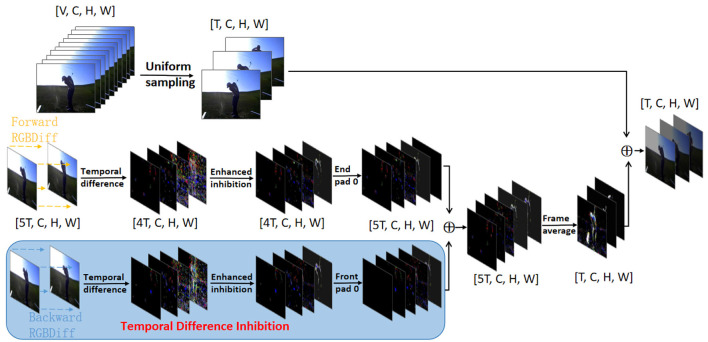
Over the past few years, a growing number of researchers have dedicated their efforts to focusing on temporal modeling. The advent of transformer-based methods has notably advanced the field of 2D image-based vision tasks. However, with respect to 3D video tasks such as action recognition, applying temporal transformations directly to video data significantly increases both computational and memory demands. This surge in resource consumption is due to the multiplication of data patches and the added complexity of self-aware computations. Accordingly, building efficient and precise 3D self-attentive models for video content represents as a major challenge for transformers. In our research, we introduce an Long and Short-term Temporal Difference Vision Transformer (LS-VIT). This method incorporates short-term motion details into images by weighting the difference across several consecutive frames, thereby equipping the original image with the ability to model short-term motions. Concurrently, we integrate a module designed to understand long-term motion details. This module enhances the model's capacity for long-term motion modeling by directly integrating temporal differences from various segments via motion excitation. Our thorough analysis confirms that the LS-VIT achieves high recognition accuracy across multiple benchmarks (e.g., UCF101, HMDB51, Kinetics-400). These research results indicate that LS-VIT has the potential for further optimization, which can improve real-time performance and action prediction capabilities.
期刊介绍:
Frontiers in Neurorobotics publishes rigorously peer-reviewed research in the science and technology of embodied autonomous neural systems. Specialty Chief Editors Alois C. Knoll and Florian Röhrbein at the Technische Universität München are supported by an outstanding Editorial Board of international experts. This multidisciplinary open-access journal is at the forefront of disseminating and communicating scientific knowledge and impactful discoveries to researchers, academics and the public worldwide.
Neural systems include brain-inspired algorithms (e.g. connectionist networks), computational models of biological neural networks (e.g. artificial spiking neural nets, large-scale simulations of neural microcircuits) and actual biological systems (e.g. in vivo and in vitro neural nets). The focus of the journal is the embodiment of such neural systems in artificial software and hardware devices, machines, robots or any other form of physical actuation. This also includes prosthetic devices, brain machine interfaces, wearable systems, micro-machines, furniture, home appliances, as well as systems for managing micro and macro infrastructures. Frontiers in Neurorobotics also aims to publish radically new tools and methods to study plasticity and development of autonomous self-learning systems that are capable of acquiring knowledge in an open-ended manner. Models complemented with experimental studies revealing self-organizing principles of embodied neural systems are welcome. Our journal also publishes on the micro and macro engineering and mechatronics of robotic devices driven by neural systems, as well as studies on the impact that such systems will have on our daily life.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


