Highly valued subgoal generation for efficient goal-conditioned reinforcement learning
IF 6
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
Goal-conditioned reinforcement learning is widely used in robot control, manipulating the robot to accomplish specific tasks by maximizing accumulated rewards. However, the useful reward signal is only received when the desired goal is reached, leading to the issue of sparse rewards and affecting the efficiency of policy learning. In this paper, we propose a method to generate highly valued subgoals for efficient goal-conditioned policy learning, enabling the development of smart home robots or automatic pilots in our daily life. The highly valued subgoals are conditioned on the context of the specific tasks and characterized by suitable complexity for efficient goal-conditioned action value learning. The context variable captures the latent representation of the particular tasks, allowing for efficient subgoal generation. Additionally, the goal-conditioned action values regularized by the self-adaptive ranges generate subgoals with suitable complexity. Compared to Hindsight Experience Replay that uniformly samples subgoals from visited trajectories, our method generates the subgoals based on the context of tasks with suitable difficulty for efficient policy training. Experimental results show that our method achieves stable performance in robotic environments compared to baseline methods.
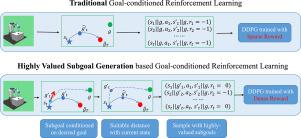
为高效目标条件强化学习生成高价值子目标
目标条件强化学习广泛应用于机器人控制,通过最大化累积奖励来操纵机器人完成特定任务。然而,只有在达到预期目标时才会收到有用的奖励信号,这就导致了奖励稀疏的问题,影响了策略学习的效率。在本文中,我们提出了一种生成高价值子目标的方法,以实现高效的目标条件策略学习,从而开发出智能家居机器人或日常生活中的自动驾驶员。高价值子目标以特定任务的上下文为条件,具有适合目标条件行动值高效学习的复杂性。上下文变量捕捉了特定任务的潜在表征,从而可以高效地生成子目标。此外,由自适应范围规范化的目标条件行动值可生成具有适当复杂度的子目标。与从访问过的轨迹中均匀采样子目标的 "后见之明经验重放 "相比,我们的方法是根据任务的上下文生成子目标,具有适当的难度,从而实现高效的策略训练。实验结果表明,与基线方法相比,我们的方法在机器人环境中实现了稳定的性能。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Neural Networks
工程技术-计算机:人工智能
CiteScore
13.90
自引率
7.70%
发文量
425
审稿时长
67 days
期刊介绍:
Neural Networks is a platform that aims to foster an international community of scholars and practitioners interested in neural networks, deep learning, and other approaches to artificial intelligence and machine learning. Our journal invites submissions covering various aspects of neural networks research, from computational neuroscience and cognitive modeling to mathematical analyses and engineering applications. By providing a forum for interdisciplinary discussions between biology and technology, we aim to encourage the development of biologically-inspired artificial intelligence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


