Addressing imbalanced data for machine learning based mineral prospectivity mapping
IF 3.2
2区 地球科学
Q1 GEOLOGY
引用次数: 0
Abstract
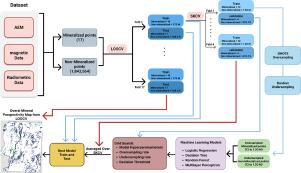
Effective Mineral Prospectivity Mapping (MPM) relies on the ability of Machine Learning (ML) models to extract meaningful patterns from geophysical data. However, in mineral exploration, identifying the presence of mineral deposits is often a rare event compared with the overall geological landscape. This rarity leads to a highly imbalanced dataset, where positive instances (mineralized samples) are considerably less frequent than negative instances (non-mineralized samples). Imbalanced data can potentially bias ML models towards the majority class, leading to inaccurate predictions for the minority class (mineralized samples) which are of primary interest. To address this challenge, we proposed two-level methods in this study. At the data level, we employed imbalanced data handling techniques that operate on the training dataset and change the class distribution. At the algorithmic level, we adjusted the decision threshold of a model to balance the trade-off between false positives and false negatives. Experimental results are collected on a geophysical data from Lapland, Finland. The dataset exhibits a significant class imbalance, comprising 17 positive samples contrasted with negative samples. We investigate the effect of handling imbalanced data on the performance of four ML models including Multi-Layer Perceptron (MLP), Random Forest (RF), Decision Tree (DT), and Logistic Regression (LR). From the results, we found that the MLP model achieved the best overall performance, with total accuracy of 97.13% on balanced data using synthetic minority oversampling method. Random forest and DT also performed well, with accuracies of 88.34% and 89.35%, respectively. The implemented methodology of this work is integrated in QGIS as a new toolkit which is called EIS Toolkit 1for MPM.
为基于机器学习的矿产远景测绘解决不平衡数据问题
有效的矿产远景测绘(MPM)依赖于机器学习(ML)模型从地球物理数据中提取有意义模式的能力。然而,在矿产勘探中,与整体地质景观相比,识别矿床的存在往往是一件罕见的事情。这种罕见性导致了数据集的高度不平衡,正实例(矿化样本)的出现频率大大低于负实例(非矿化样本)。不平衡的数据可能会使 ML 模型偏向于多数类,从而导致对主要关注的少数类(矿化样本)的预测不准确。为了应对这一挑战,我们在本研究中提出了两级方法。在数据层面,我们采用了不平衡数据处理技术,对训练数据集进行操作并改变类别分布。在算法层面,我们调整了模型的决策阈值,以平衡假阳性和假阴性之间的权衡。实验结果收集自芬兰拉普兰的地球物理数据。该数据集显示出明显的类不平衡,包括 17 个阳性样本和 1.84×106 个阴性样本。我们研究了处理不平衡数据对四种 ML 模型性能的影响,包括多层感知器(MLP)、随机森林(RF)、决策树(DT)和逻辑回归(LR)。从结果来看,我们发现 MLP 模型的整体性能最好,在使用合成少数群体超采样方法的平衡数据上,总准确率达到 97.13%。随机森林和 DT 也表现出色,准确率分别为 88.34% 和 89.35%。这项工作所实施的方法被集成到 QGIS 中,成为一个新的工具包,名为 EIS Toolkit 1 for MPM。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Ore Geology Reviews
地学-地质学
CiteScore
6.50
自引率
27.30%
发文量
546
审稿时长
22.9 weeks
期刊介绍:
Ore Geology Reviews aims to familiarize all earth scientists with recent advances in a number of interconnected disciplines related to the study of, and search for, ore deposits. The reviews range from brief to longer contributions, but the journal preferentially publishes manuscripts that fill the niche between the commonly shorter journal articles and the comprehensive book coverages, and thus has a special appeal to many authors and readers.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


