Fine-grained Automatic Augmentation for handwritten character recognition
IF 7.5
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
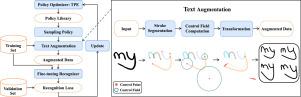
With the advancement of deep learning-based character recognition models, the training data size has become a crucial factor in improving the performance of handwritten text recognition. For languages with low-resource handwriting samples, data augmentation methods can effectively scale up the data size and improve the performance of handwriting recognition models. However, existing data augmentation methods for handwritten text face two limitations: (1) Methods based on global spatial transformations typically augment the training data by transforming each word sample as a whole but ignore the potential to generate fine-grained transformation from local word areas, limiting the diversity of the generated samples; (2) It is challenging to adaptively choose a reasonable augmentation parameter when applying these methods to different language datasets. To address these issues, this paper proposes Fine-grained Automatic Augmentation (FgAA) for handwritten character recognition. Specifically, FgAA views each word sample as composed of multiple strokes and achieves data augmentation by performing fine-grained transformations on the strokes. Each word is automatically segmented into various strokes, and each stroke is fitted with a Bézier curve. On such a basis, we define the augmentation policy related to the fine-grained transformation and use Bayesian optimization to select the optimal augmentation policy automatically, thereby achieving the automatic augmentation of handwriting samples. Experiments on seven handwriting datasets of different languages demonstrate that FgAA achieves the best augmentation effect for handwritten character recognition. Our code is available at https://github.com/IMU-MachineLearningSXD/Fine-grained-Automatic-Augmentation
用于手写字符识别的细粒度自动增强技术
随着基于深度学习的字符识别模型的发展,训练数据规模已成为提高手写文本识别性能的关键因素。对于手写样本资源较少的语言,数据扩增方法可以有效扩大数据规模,提高手写识别模型的性能。然而,现有的手写文本数据增强方法面临两个局限性:(1)基于全局空间变换的方法通常通过对每个单词样本进行整体变换来增强训练数据,但忽略了从局部单词区域生成细粒度变换的潜力,从而限制了生成样本的多样性;(2)将这些方法应用于不同语言数据集时,如何自适应地选择合理的增强参数具有挑战性。为了解决这些问题,本文提出了用于手写字符识别的细粒度自动增强(FgAA)方法。具体来说,FgAA 将每个单词样本视为由多个笔画组成,并通过对笔画进行细粒度变换来实现数据增强。每个字被自动分割成不同的笔画,每个笔画都用贝塞尔曲线拟合。在此基础上,我们定义了与细粒度变换相关的扩增策略,并使用贝叶斯优化法自动选择最优扩增策略,从而实现手写样本的自动扩增。在七个不同语言的手写数据集上进行的实验表明,FgAA 在手写字符识别方面取得了最佳的增强效果。我们的代码见 https://github.com/IMU-MachineLearningSXD/Fine-grained-Automatic-Augmentation
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Pattern Recognition
工程技术-工程:电子与电气
CiteScore
14.40
自引率
16.20%
发文量
683
审稿时长
5.6 months
期刊介绍:
The field of Pattern Recognition is both mature and rapidly evolving, playing a crucial role in various related fields such as computer vision, image processing, text analysis, and neural networks. It closely intersects with machine learning and is being applied in emerging areas like biometrics, bioinformatics, multimedia data analysis, and data science. The journal Pattern Recognition, established half a century ago during the early days of computer science, has since grown significantly in scope and influence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


