Geanderson Santos, Igor Muzetti, Eduardo Figueiredo
{"title":"Two sides of the same coin: A study on developers' perception of defects","authors":"Geanderson Santos, Igor Muzetti, Eduardo Figueiredo","doi":"10.1002/smr.2699","DOIUrl":null,"url":null,"abstract":"<div>\n \n <p>Software defect prediction is a subject of study involving the interplay of software engineering and machine learning. The current literature proposed numerous machine learning models to predict software defects from software data, such as commits and code metrics. Further, the most recent literature employs explainability techniques to understand why machine learning models made such predictions (i.e., predicting the likelihood of a defect). As a result, developers are expected to reason on the software features that may relate to defects in the source code. However, little is known about the developers' perception of these machine learning models and their explanations. To explore this issue, we focus on a survey with experienced developers to understand how they evaluate each quality attribute for the defect prediction. We chose the developers based on their contributions at GitHub, where they contributed to at least 10 repositories in the past 2 years. The results show that developers tend to evaluate code complexity as the most important quality attribute to avoid defects compared with the other target attributes such as source code size, coupling, and documentation. At the end, a thematic analysis reveals that developers evaluate testing the code as a relevant aspect not covered by the static software features. We conclude that, qualitatively, there exists a misalignment between developers' perceptions and the outputs of machine learning models. For instance, while machine learning models assign high importance to documentation, developers often overlook documentation and prioritize assessing the complexity of the code instead.</p>\n </div>","PeriodicalId":48898,"journal":{"name":"Journal of Software-Evolution and Process","volume":"36 10","pages":""},"PeriodicalIF":1.7000,"publicationDate":"2024-06-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Software-Evolution and Process","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/smr.2699","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
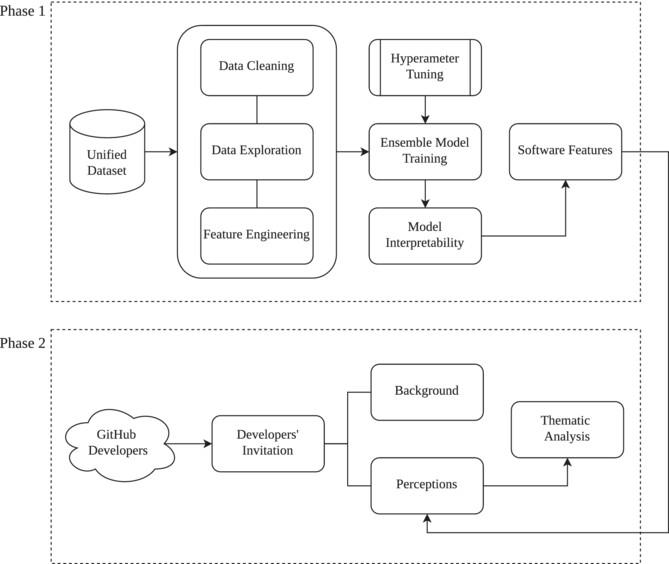
Software defect prediction is a subject of study involving the interplay of software engineering and machine learning. The current literature proposed numerous machine learning models to predict software defects from software data, such as commits and code metrics. Further, the most recent literature employs explainability techniques to understand why machine learning models made such predictions (i.e., predicting the likelihood of a defect). As a result, developers are expected to reason on the software features that may relate to defects in the source code. However, little is known about the developers' perception of these machine learning models and their explanations. To explore this issue, we focus on a survey with experienced developers to understand how they evaluate each quality attribute for the defect prediction. We chose the developers based on their contributions at GitHub, where they contributed to at least 10 repositories in the past 2 years. The results show that developers tend to evaluate code complexity as the most important quality attribute to avoid defects compared with the other target attributes such as source code size, coupling, and documentation. At the end, a thematic analysis reveals that developers evaluate testing the code as a relevant aspect not covered by the static software features. We conclude that, qualitatively, there exists a misalignment between developers' perceptions and the outputs of machine learning models. For instance, while machine learning models assign high importance to documentation, developers often overlook documentation and prioritize assessing the complexity of the code instead.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


