Comparing Machine Learning and Advanced Methods with Traditional Methods to Generate Weights in Inverse Probability of Treatment Weighting: The INFORM Study.
{"title":"Comparing Machine Learning and Advanced Methods with Traditional Methods to Generate Weights in Inverse Probability of Treatment Weighting: The INFORM Study.","authors":"Doyoung Kwak, Yuanjie Liang, Xu Shi, Xi Tan","doi":"10.2147/POR.S466505","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>Observational research provides valuable insights into treatments used in patient populations in real-world settings. However, confounding is likely to occur if there are differences in patient characteristics associated with both the exposure and outcome between the groups being evaluated. One approach to reduce confounding and facilitate unbiased comparisons is inverse probability of treatment weighting (IPTW) using propensity scores. Machine learning (ML) and entropy balancing can potentially be used in generating propensity scores for IPTW, but there is limited literature on this application. We aimed to assess the feasibility of applying these methods for reducing confounding in observational studies. These methods were assessed in a study comparing cardiovascular outcomes in adults with type 2 diabetes and established atherosclerotic cardiovascular disease taking once-weekly glucagon-like peptide-1 receptor agonists or dipeptidyl peptidase-4 inhibitors.</p><p><strong>Methods: </strong>We applied advanced methods to generate the propensity scores compared to the original logistic regression method in terms of covariate balance. After calculating weights, a weighted Cox proportional hazards model was used to calculate the sample average treatment effect. Support Vector Classification, Support Vector Regression, XGBoost, and LightGBM were the ML models used. Entropy balancing was also performed on features identified in the original cardiovascular outcomes study.</p><p><strong>Results: </strong>Accuracy (range: 0.71 to 0.73), area under the curve (0.77 to 0.79), precision (0.53 to 0.60), recall (0.66 to 0.68), and F1 score (0.60 to 0.64) were similar between all of the advanced propensity score methods and traditional logistic regression. Among ML models, only XGBoost achieved balance in all measured baseline characteristics between the two treatment groups, closely approximating the performance of the original logistic regression. Entropy balancing weights provided the best performance among all models in balancing baseline characteristics, achieving near perfect balancing.</p><p><strong>Conclusion: </strong>Among the advanced methods examined, entropy balancing weights performed the best for optimizing balancing and can produce similar results compared to traditional logistic regression.</p>","PeriodicalId":20399,"journal":{"name":"Pragmatic and Observational Research","volume":"15 ","pages":"173-183"},"PeriodicalIF":2.7000,"publicationDate":"2024-10-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11462432/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Pragmatic and Observational Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2147/POR.S466505","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MEDICINE, GENERAL & INTERNAL","Score":null,"Total":0}
引用次数: 0
Abstract
Purpose: Observational research provides valuable insights into treatments used in patient populations in real-world settings. However, confounding is likely to occur if there are differences in patient characteristics associated with both the exposure and outcome between the groups being evaluated. One approach to reduce confounding and facilitate unbiased comparisons is inverse probability of treatment weighting (IPTW) using propensity scores. Machine learning (ML) and entropy balancing can potentially be used in generating propensity scores for IPTW, but there is limited literature on this application. We aimed to assess the feasibility of applying these methods for reducing confounding in observational studies. These methods were assessed in a study comparing cardiovascular outcomes in adults with type 2 diabetes and established atherosclerotic cardiovascular disease taking once-weekly glucagon-like peptide-1 receptor agonists or dipeptidyl peptidase-4 inhibitors.
Methods: We applied advanced methods to generate the propensity scores compared to the original logistic regression method in terms of covariate balance. After calculating weights, a weighted Cox proportional hazards model was used to calculate the sample average treatment effect. Support Vector Classification, Support Vector Regression, XGBoost, and LightGBM were the ML models used. Entropy balancing was also performed on features identified in the original cardiovascular outcomes study.
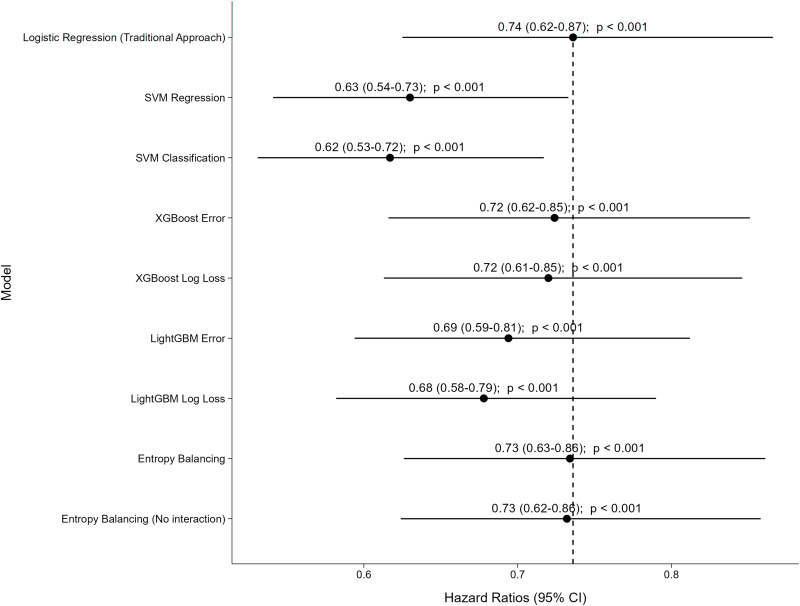
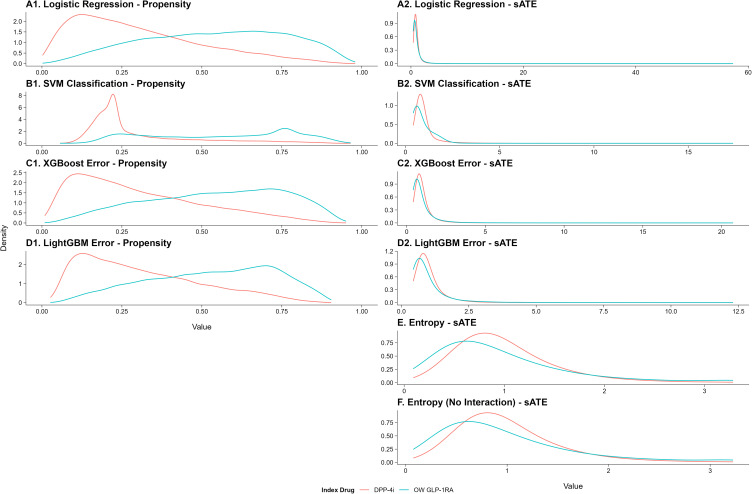
Results: Accuracy (range: 0.71 to 0.73), area under the curve (0.77 to 0.79), precision (0.53 to 0.60), recall (0.66 to 0.68), and F1 score (0.60 to 0.64) were similar between all of the advanced propensity score methods and traditional logistic regression. Among ML models, only XGBoost achieved balance in all measured baseline characteristics between the two treatment groups, closely approximating the performance of the original logistic regression. Entropy balancing weights provided the best performance among all models in balancing baseline characteristics, achieving near perfect balancing.
Conclusion: Among the advanced methods examined, entropy balancing weights performed the best for optimizing balancing and can produce similar results compared to traditional logistic regression.
期刊介绍:
Pragmatic and Observational Research is an international, peer-reviewed, open-access journal that publishes data from studies designed to closely reflect medical interventions in real-world clinical practice, providing insights beyond classical randomized controlled trials (RCTs). While RCTs maximize internal validity for cause-and-effect relationships, they often represent only specific patient groups. This journal aims to complement such studies by providing data that better mirrors real-world patients and the usage of medicines, thus informing guidelines and enhancing the applicability of research findings across diverse patient populations encountered in everyday clinical practice.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


