Evaluation of Care Quality for Atrial Fibrillation Across Non-Interoperable Electronic Health Record Data using a Retrieval-Augmented Generation-enabled Large Language Model.
Philip Adejumo, Phyllis M Thangaraj, Lovedeep S Dhingra, Dhruva Biswas, Arya Aminorroaya, Sumukh Vasisht Shankar, Aline F Pedroso, Philip M Croon, Rohan Khera
{"title":"Evaluation of Care Quality for Atrial Fibrillation Across Non-Interoperable Electronic Health Record Data using a Retrieval-Augmented Generation-enabled Large Language Model.","authors":"Philip Adejumo, Phyllis M Thangaraj, Lovedeep S Dhingra, Dhruva Biswas, Arya Aminorroaya, Sumukh Vasisht Shankar, Aline F Pedroso, Philip M Croon, Rohan Khera","doi":"10.1101/2024.09.19.24313992","DOIUrl":null,"url":null,"abstract":"<p><strong>Importance: </strong>Standardized assessment of clinical quality measures from electronic health records (EHRs) is challenging because information is fragmented across structured and unstructured data, and due to low interoperability across systems. Traditionally, extracting this information requires manual EHR abstraction, a time-consuming and expensive process that also limits real-time care quality improvement. <b>Objective:</b> To evaluate whether a data format-agnostic retrieval-augmented generation-enabled large language model (RAG-LLM) can accurately abstract clinical variables from heterogeneous structured and unstructured EHR data.</p><p><strong>Design setting and participants: </strong>Retrospective cross-sectional study assessing stroke and bleeding risk in patients with atrial fibrillation (AF) from two health systems. We developed a RAG-LLM model to extract CHA DS-VASc and HAS-BLED risk factors from tabular data and clinical documentation.The framework was validated on 300 expert-annotated patient records (200 from Yale New Haven Health System [YNHHS] and 100 from the Medical Information Mart for Intensive Care [MIMIC-IV]). The system was deployed on two large cohorts: 104,204 patients with AF from YNHHS (2013-2024) and 13,117 from MIMIC-IV (2008-2022). We compared anticoagulation recommendations derived from RAG-LLM with those based on traditional structured data abstraction.</p><p><strong>Exposures: </strong>Use of a RAG-LLM model to abstract stroke and bleeding risk factors from structured and unstructured EHR data.</p><p><strong>Main outcomes and measures: </strong>Accuracy of RAG-LLM-based risk factor abstraction against expert annotation. Secondary outcomes included efficiency, cross-cohort generalizability, and impact on anticoagulation eligibility based on risk stratification.</p><p><strong>Results: </strong>In the validation cohort (mean age 74.8 years, 42.7% female), RAG-LLM demonstrated superior performance across all metrics compared with structural data abstraction. For individual CHA DS-VASc components, accuracy ranged from 0.94-1.00 (YNHHS) and 0.89-1.00 (MIMIC-IV) versus 0.66-0.92 (YNHHS) and 0.44-0.97 (MIMIC-IV) for structured data, which was similar for HAS-BLED (0.94-1.00 and 0.89-1.00 vs 0.66-0.94 and 0.44-0.97). In the deployment study, among 3,207 patients classified as low/intermediate stroke risk with structured data, 62.1% (1,993) were reclassified as high risk with RAG-LLM and would become eligible for anticoagulation. Similarly, 5.5% of those classified as low bleeding risk by structured data were reclassified as high risk, substantially refining contraindication assessment.</p><p><strong>Conclusions: </strong>A multimodal RAG-LLM accurately abstracts clinical variables from structured and unstructured EHR data to improve stroke and bleeding risk assessments in patients with AF, enhancing identification of appropriate anticoagulation candidates.</p>","PeriodicalId":94281,"journal":{"name":"medRxiv : the preprint server for health sciences","volume":" ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2025-09-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11451809/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"medRxiv : the preprint server for health sciences","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1101/2024.09.19.24313992","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Importance: Standardized assessment of clinical quality measures from electronic health records (EHRs) is challenging because information is fragmented across structured and unstructured data, and due to low interoperability across systems. Traditionally, extracting this information requires manual EHR abstraction, a time-consuming and expensive process that also limits real-time care quality improvement. Objective: To evaluate whether a data format-agnostic retrieval-augmented generation-enabled large language model (RAG-LLM) can accurately abstract clinical variables from heterogeneous structured and unstructured EHR data.
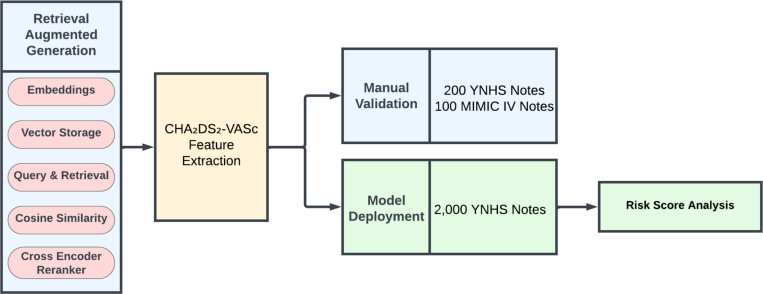
Design setting and participants: Retrospective cross-sectional study assessing stroke and bleeding risk in patients with atrial fibrillation (AF) from two health systems. We developed a RAG-LLM model to extract CHA DS-VASc and HAS-BLED risk factors from tabular data and clinical documentation.The framework was validated on 300 expert-annotated patient records (200 from Yale New Haven Health System [YNHHS] and 100 from the Medical Information Mart for Intensive Care [MIMIC-IV]). The system was deployed on two large cohorts: 104,204 patients with AF from YNHHS (2013-2024) and 13,117 from MIMIC-IV (2008-2022). We compared anticoagulation recommendations derived from RAG-LLM with those based on traditional structured data abstraction.
Exposures: Use of a RAG-LLM model to abstract stroke and bleeding risk factors from structured and unstructured EHR data.
Main outcomes and measures: Accuracy of RAG-LLM-based risk factor abstraction against expert annotation. Secondary outcomes included efficiency, cross-cohort generalizability, and impact on anticoagulation eligibility based on risk stratification.
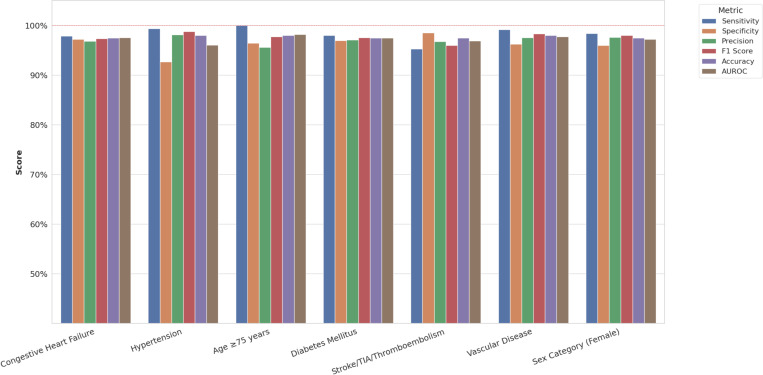
Results: In the validation cohort (mean age 74.8 years, 42.7% female), RAG-LLM demonstrated superior performance across all metrics compared with structural data abstraction. For individual CHA DS-VASc components, accuracy ranged from 0.94-1.00 (YNHHS) and 0.89-1.00 (MIMIC-IV) versus 0.66-0.92 (YNHHS) and 0.44-0.97 (MIMIC-IV) for structured data, which was similar for HAS-BLED (0.94-1.00 and 0.89-1.00 vs 0.66-0.94 and 0.44-0.97). In the deployment study, among 3,207 patients classified as low/intermediate stroke risk with structured data, 62.1% (1,993) were reclassified as high risk with RAG-LLM and would become eligible for anticoagulation. Similarly, 5.5% of those classified as low bleeding risk by structured data were reclassified as high risk, substantially refining contraindication assessment.
Conclusions: A multimodal RAG-LLM accurately abstracts clinical variables from structured and unstructured EHR data to improve stroke and bleeding risk assessments in patients with AF, enhancing identification of appropriate anticoagulation candidates.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


