Paulina Körner, Juliane Glüge, Stefan Glüge and Martin Scheringer
{"title":"Critical insights into data curation and label noise for accurate prediction of aerobic biodegradability of organic chemicals†","authors":"Paulina Körner, Juliane Glüge, Stefan Glüge and Martin Scheringer","doi":"10.1039/D4EM00431K","DOIUrl":null,"url":null,"abstract":"<p >The focus of this work is to enhance state-of-the-art Machine Learning (ML) models that can predict the aerobic biodegradability of organic chemicals through a data-centric approach. To do that, an already existing dataset that was previously used to train ML models was analyzed for mismatching chemical identifiers and data leakage between test and training set and the detected errors were corrected. Chemicals with high variance between study results were removed and an XGBoost was trained on the dataset. Despite extensive data curation, only marginal improvement was achieved in the classification model's performance. This was attributed to three potential reasons: (1) a significant number of data labels were noisy, (2) the features could not sufficiently represent the chemicals, and/or (3) the model struggled to learn and generalize effectively. All three potential reasons were examined and point (1) seemed to be the most decisive one that prevented the model from generating more accurate results. Removing data points with possibly noisy labels by performing label noise filtering using two other predictive models increased the classification model's balanced accuracy from 80.9% to 94.2%. The new classifier is therefore better than any previously developed classification model for ready biodegradation. The examination of the key characteristics (molecular weight of the substances, proportion of halogens present and distribution of degradation labels) and the applicability domain indicate that no/not a large share of difficult-to-learn substances has been removed in the label noise filtering, meaning that the final model is still very robust.</p>","PeriodicalId":74,"journal":{"name":"Environmental Science: Processes & Impacts","volume":" 10","pages":" 1780-1795"},"PeriodicalIF":4.3000,"publicationDate":"2024-09-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://pubs.rsc.org/en/content/articlepdf/2024/em/d4em00431k?page=search","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Environmental Science: Processes & Impacts","FirstCategoryId":"93","ListUrlMain":"https://pubs.rsc.org/en/content/articlelanding/2024/em/d4em00431k","RegionNum":3,"RegionCategory":"环境科学与生态学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, ANALYTICAL","Score":null,"Total":0}
引用次数: 0
Abstract
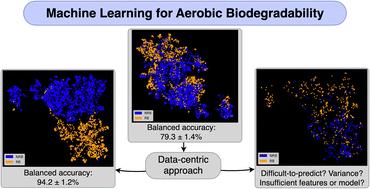
The focus of this work is to enhance state-of-the-art Machine Learning (ML) models that can predict the aerobic biodegradability of organic chemicals through a data-centric approach. To do that, an already existing dataset that was previously used to train ML models was analyzed for mismatching chemical identifiers and data leakage between test and training set and the detected errors were corrected. Chemicals with high variance between study results were removed and an XGBoost was trained on the dataset. Despite extensive data curation, only marginal improvement was achieved in the classification model's performance. This was attributed to three potential reasons: (1) a significant number of data labels were noisy, (2) the features could not sufficiently represent the chemicals, and/or (3) the model struggled to learn and generalize effectively. All three potential reasons were examined and point (1) seemed to be the most decisive one that prevented the model from generating more accurate results. Removing data points with possibly noisy labels by performing label noise filtering using two other predictive models increased the classification model's balanced accuracy from 80.9% to 94.2%. The new classifier is therefore better than any previously developed classification model for ready biodegradation. The examination of the key characteristics (molecular weight of the substances, proportion of halogens present and distribution of degradation labels) and the applicability domain indicate that no/not a large share of difficult-to-learn substances has been removed in the label noise filtering, meaning that the final model is still very robust.
期刊介绍:
Environmental Science: Processes & Impacts publishes high quality papers in all areas of the environmental chemical sciences, including chemistry of the air, water, soil and sediment. We welcome studies on the environmental fate and effects of anthropogenic and naturally occurring contaminants, both chemical and microbiological, as well as related natural element cycling processes.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


