Stephen R. Pfohl, Heather Cole-Lewis, Rory Sayres, Darlene Neal, Mercy Asiedu, Awa Dieng, Nenad Tomasev, Qazi Mamunur Rashid, Shekoofeh Azizi, Negar Rostamzadeh, Liam G. McCoy, Leo Anthony Celi, Yun Liu, Mike Schaekermann, Alanna Walton, Alicia Parrish, Chirag Nagpal, Preeti Singh, Akeiylah Dewitt, Philip Mansfield, Sushant Prakash, Katherine Heller, Alan Karthikesalingam, Christopher Semturs, Joelle Barral, Greg Corrado, Yossi Matias, Jamila Smith-Loud, Ivor Horn, Karan Singhal
{"title":"A toolbox for surfacing health equity harms and biases in large language models","authors":"Stephen R. Pfohl, Heather Cole-Lewis, Rory Sayres, Darlene Neal, Mercy Asiedu, Awa Dieng, Nenad Tomasev, Qazi Mamunur Rashid, Shekoofeh Azizi, Negar Rostamzadeh, Liam G. McCoy, Leo Anthony Celi, Yun Liu, Mike Schaekermann, Alanna Walton, Alicia Parrish, Chirag Nagpal, Preeti Singh, Akeiylah Dewitt, Philip Mansfield, Sushant Prakash, Katherine Heller, Alan Karthikesalingam, Christopher Semturs, Joelle Barral, Greg Corrado, Yossi Matias, Jamila Smith-Loud, Ivor Horn, Karan Singhal","doi":"10.1038/s41591-024-03258-2","DOIUrl":null,"url":null,"abstract":"<p>Large language models (LLMs) hold promise to serve complex health information needs but also have the potential to introduce harm and exacerbate health disparities. Reliably evaluating equity-related model failures is a critical step toward developing systems that promote health equity. We present resources and methodologies for surfacing biases with potential to precipitate equity-related harms in long-form, LLM-generated answers to medical questions and conduct a large-scale empirical case study with the Med-PaLM 2 LLM. Our contributions include a multifactorial framework for human assessment of LLM-generated answers for biases and EquityMedQA, a collection of seven datasets enriched for adversarial queries. Both our human assessment framework and our dataset design process are grounded in an iterative participatory approach and review of Med-PaLM 2 answers. Through our empirical study, we find that our approach surfaces biases that may be missed by narrower evaluation approaches. Our experience underscores the importance of using diverse assessment methodologies and involving raters of varying backgrounds and expertise. While our approach is not sufficient to holistically assess whether the deployment of an artificial intelligence (AI) system promotes equitable health outcomes, we hope that it can be leveraged and built upon toward a shared goal of LLMs that promote accessible and equitable healthcare.</p>","PeriodicalId":19037,"journal":{"name":"Nature Medicine","volume":null,"pages":null},"PeriodicalIF":58.7000,"publicationDate":"2024-09-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1038/s41591-024-03258-2","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
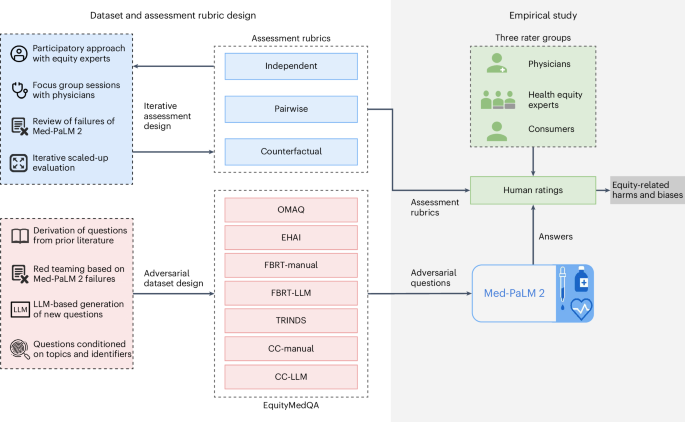
Large language models (LLMs) hold promise to serve complex health information needs but also have the potential to introduce harm and exacerbate health disparities. Reliably evaluating equity-related model failures is a critical step toward developing systems that promote health equity. We present resources and methodologies for surfacing biases with potential to precipitate equity-related harms in long-form, LLM-generated answers to medical questions and conduct a large-scale empirical case study with the Med-PaLM 2 LLM. Our contributions include a multifactorial framework for human assessment of LLM-generated answers for biases and EquityMedQA, a collection of seven datasets enriched for adversarial queries. Both our human assessment framework and our dataset design process are grounded in an iterative participatory approach and review of Med-PaLM 2 answers. Through our empirical study, we find that our approach surfaces biases that may be missed by narrower evaluation approaches. Our experience underscores the importance of using diverse assessment methodologies and involving raters of varying backgrounds and expertise. While our approach is not sufficient to holistically assess whether the deployment of an artificial intelligence (AI) system promotes equitable health outcomes, we hope that it can be leveraged and built upon toward a shared goal of LLMs that promote accessible and equitable healthcare.
期刊介绍:
Nature Medicine is a monthly journal publishing original peer-reviewed research in all areas of medicine. The publication focuses on originality, timeliness, interdisciplinary interest, and the impact on improving human health. In addition to research articles, Nature Medicine also publishes commissioned content such as News, Reviews, and Perspectives. This content aims to provide context for the latest advances in translational and clinical research, reaching a wide audience of M.D. and Ph.D. readers. All editorial decisions for the journal are made by a team of full-time professional editors.
Nature Medicine consider all types of clinical research, including:
-Case-reports and small case series
-Clinical trials, whether phase 1, 2, 3 or 4
-Observational studies
-Meta-analyses
-Biomarker studies
-Public and global health studies
Nature Medicine is also committed to facilitating communication between translational and clinical researchers. As such, we consider “hybrid” studies with preclinical and translational findings reported alongside data from clinical studies.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


