Kevin D. Shabahang, Hyungwook Yim, Simon J. Dennis
{"title":"Latent Relations at Steady-state with Associative Nets","authors":"Kevin D. Shabahang, Hyungwook Yim, Simon J. Dennis","doi":"10.1111/cogs.13494","DOIUrl":null,"url":null,"abstract":"<p>Models of word meaning that exploit patterns of word usage across large text corpora to capture semantic relations, like the topic model and word2vec, condense word-by-context co-occurrence statistics to induce representations that organize words along semantically relevant dimensions (e.g., synonymy, antonymy, hyponymy, etc.). However, their reliance on latent representations leaves them vulnerable to interference, makes them slow learners, and commits to a dual-systems account of episodic and semantic memory. We show how it is possible to construct the meaning of words online during retrieval to avoid these limitations. We implement a spreading activation account of word meaning in an associative net, a one-layer highly recurrent network of associations, called a Dynamic-Eigen-Net, that we developed to address the limitations of earlier variants of associative nets when scaling up to deal with unstructured input domains like natural language text. We show that spreading activation using a one-hot coded Dynamic-Eigen-Net outperforms the topic model and reaches similar levels of performance as word2vec when predicting human free associations and word similarity ratings. Latent Semantic Analysis vectors reached similar levels of performance when constructed by applying dimensionality reduction to the Shifted Positive Pointwise Mutual Information but showed poorer predictability for free associations when using an entropy-based normalization. An analysis of the rate at which the Dynamic-Eigen-Net reaches asymptotic performance shows that it learns faster than word2vec. We argue in favor of the Dynamic-Eigen-Net as a fast learner, with a single-store, that is not subject to catastrophic interference. We present it as an alternative to instance models when delegating the induction of latent relationships to process assumptions instead of assumptions about representation.</p>","PeriodicalId":48349,"journal":{"name":"Cognitive Science","volume":"48 9","pages":""},"PeriodicalIF":2.3000,"publicationDate":"2024-09-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/cogs.13494","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Cognitive Science","FirstCategoryId":"102","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/cogs.13494","RegionNum":2,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PSYCHOLOGY, EXPERIMENTAL","Score":null,"Total":0}
引用次数: 0
Abstract
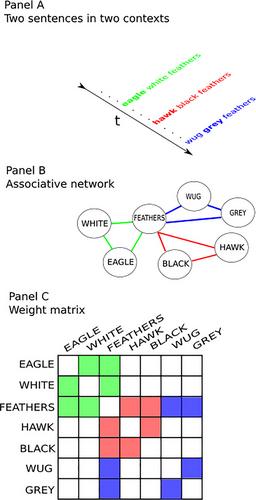
Models of word meaning that exploit patterns of word usage across large text corpora to capture semantic relations, like the topic model and word2vec, condense word-by-context co-occurrence statistics to induce representations that organize words along semantically relevant dimensions (e.g., synonymy, antonymy, hyponymy, etc.). However, their reliance on latent representations leaves them vulnerable to interference, makes them slow learners, and commits to a dual-systems account of episodic and semantic memory. We show how it is possible to construct the meaning of words online during retrieval to avoid these limitations. We implement a spreading activation account of word meaning in an associative net, a one-layer highly recurrent network of associations, called a Dynamic-Eigen-Net, that we developed to address the limitations of earlier variants of associative nets when scaling up to deal with unstructured input domains like natural language text. We show that spreading activation using a one-hot coded Dynamic-Eigen-Net outperforms the topic model and reaches similar levels of performance as word2vec when predicting human free associations and word similarity ratings. Latent Semantic Analysis vectors reached similar levels of performance when constructed by applying dimensionality reduction to the Shifted Positive Pointwise Mutual Information but showed poorer predictability for free associations when using an entropy-based normalization. An analysis of the rate at which the Dynamic-Eigen-Net reaches asymptotic performance shows that it learns faster than word2vec. We argue in favor of the Dynamic-Eigen-Net as a fast learner, with a single-store, that is not subject to catastrophic interference. We present it as an alternative to instance models when delegating the induction of latent relationships to process assumptions instead of assumptions about representation.
期刊介绍:
Cognitive Science publishes articles in all areas of cognitive science, covering such topics as knowledge representation, inference, memory processes, learning, problem solving, planning, perception, natural language understanding, connectionism, brain theory, motor control, intentional systems, and other areas of interdisciplinary concern. Highest priority is given to research reports that are specifically written for a multidisciplinary audience. The audience is primarily researchers in cognitive science and its associated fields, including anthropologists, education researchers, psychologists, philosophers, linguists, computer scientists, neuroscientists, and roboticists.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


