Seung Hyun Lee, Sieun Kim, Wonmin Byeon, Gyeongrok Oh, Sumin In, Hyeongcheol Park, Sang Ho Yoon, Sung-Hee Hong, Jinkyu Kim, Sangpil Kim
{"title":"Audio-guided implicit neural representation for local image stylization","authors":"Seung Hyun Lee, Sieun Kim, Wonmin Byeon, Gyeongrok Oh, Sumin In, Hyeongcheol Park, Sang Ho Yoon, Sung-Hee Hong, Jinkyu Kim, Sangpil Kim","doi":"10.1007/s41095-024-0413-5","DOIUrl":null,"url":null,"abstract":"<p>We present a novel framework for audio-guided localized image stylization. Sound often provides information about the specific context of a scene and is closely related to a certain part of the scene or object. However, existing image stylization works have focused on stylizing the entire image using an image or text input. Stylizing a particular part of the image based on audio input is natural but challenging. This work proposes a framework in which a user provides an audio input to localize the target in the input image and another to locally stylize the target object or scene. We first produce a fine localization map using an audio-visual localization network leveraging CLIP embedding space. We then utilize an implicit neural representation (INR) along with the predicted localization map to stylize the target based on sound information. The INR manipulates local pixel values to be semantically consistent with the provided audio input. Our experiments show that the proposed framework outperforms other audio-guided stylization methods. Moreover, we observe that our method constructs concise localization maps and naturally manipulates the target object or scene in accordance with the given audio input.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"37 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-08-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-024-0413-5","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
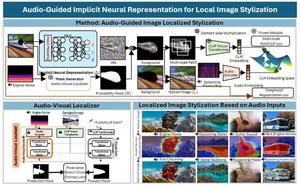
We present a novel framework for audio-guided localized image stylization. Sound often provides information about the specific context of a scene and is closely related to a certain part of the scene or object. However, existing image stylization works have focused on stylizing the entire image using an image or text input. Stylizing a particular part of the image based on audio input is natural but challenging. This work proposes a framework in which a user provides an audio input to localize the target in the input image and another to locally stylize the target object or scene. We first produce a fine localization map using an audio-visual localization network leveraging CLIP embedding space. We then utilize an implicit neural representation (INR) along with the predicted localization map to stylize the target based on sound information. The INR manipulates local pixel values to be semantically consistent with the provided audio input. Our experiments show that the proposed framework outperforms other audio-guided stylization methods. Moreover, we observe that our method constructs concise localization maps and naturally manipulates the target object or scene in accordance with the given audio input.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


