Jiaao Li, Yixiang Huang, Ming Wu, Bin Zhang, Xu Ji, Chuang Zhang
{"title":"CLIP-SP: Vision-language model with adaptive prompting for scene parsing","authors":"Jiaao Li, Yixiang Huang, Ming Wu, Bin Zhang, Xu Ji, Chuang Zhang","doi":"10.1007/s41095-024-0430-4","DOIUrl":null,"url":null,"abstract":"<p>We present a novel framework, CLIP-SP, and a novel adaptive prompt method to leverage pre-trained knowledge from CLIP for scene parsing. Our approach addresses the limitations of DenseCLIP, which demonstrates the superior image segmentation provided by CLIP pre-trained models over ImageNet pre-trained models, but struggles with rough pixel-text score maps for complex scene parsing. We argue that, as they contain all textual information in a dataset, the pixel-text score maps, i.e., dense prompts, are inevitably mixed with noise. To overcome this challenge, we propose a two-step method. Firstly, we extract visual and language features and perform multi-label classification to identify the most likely categories in the input images. Secondly, based on the top-<i>k</i> categories and confidence scores, our method generates scene tokens which can be treated as adaptive prompts for implicit modeling of scenes, and incorporates them into the visual features fed into the decoder for segmentation. Our method imposes a constraint on prompts and suppresses the probability of irrelevant categories appearing in the scene parsing results. Our method achieves competitive performance, limited by the available visual-language pre-trained models. Our CLIP-SP performs 1.14% better (in terms of mIoU) than DenseCLIP on ADE20K, using a ResNet-50 backbone.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"40 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-08-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-024-0430-4","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
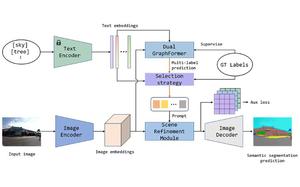
We present a novel framework, CLIP-SP, and a novel adaptive prompt method to leverage pre-trained knowledge from CLIP for scene parsing. Our approach addresses the limitations of DenseCLIP, which demonstrates the superior image segmentation provided by CLIP pre-trained models over ImageNet pre-trained models, but struggles with rough pixel-text score maps for complex scene parsing. We argue that, as they contain all textual information in a dataset, the pixel-text score maps, i.e., dense prompts, are inevitably mixed with noise. To overcome this challenge, we propose a two-step method. Firstly, we extract visual and language features and perform multi-label classification to identify the most likely categories in the input images. Secondly, based on the top-k categories and confidence scores, our method generates scene tokens which can be treated as adaptive prompts for implicit modeling of scenes, and incorporates them into the visual features fed into the decoder for segmentation. Our method imposes a constraint on prompts and suppresses the probability of irrelevant categories appearing in the scene parsing results. Our method achieves competitive performance, limited by the available visual-language pre-trained models. Our CLIP-SP performs 1.14% better (in terms of mIoU) than DenseCLIP on ADE20K, using a ResNet-50 backbone.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


