{"title":"Multi-agent reinforcement learning in a new transactive energy mechanism","authors":"Hossein Mohsenzadeh-Yazdi, Hamed Kebriaei, Farrokh Aminifar","doi":"10.1049/gtd2.13244","DOIUrl":null,"url":null,"abstract":"<p>Thanks to reinforcement learning (RL), decision-making is more convenient and more economical in different situations with high uncertainty. In line with the same fact, it is proposed that prosumers can apply RL to earn more profit in the transactive energy market (TEM). In this article, an environment that represents a novel framework of TEM is designed, where all participants send their bids to this framework and receive their profit from it. Also, new state-action spaces are designed for sellers and buyers so that they can apply the Soft Actor-Critic (SAC) algorithm to converge to the best policy. A brief of this algorithm, which is for continuous state-action space, is described. First, this algorithm is implemented for a single agent (a seller and a buyer). Then we consider all players including sellers and buyers who can apply this algorithm as Multi-Agent. In this situation, there is a comprehensive game between participants that is investigated, and it is analyzed whether the players converge to the Nash equilibrium (NE) in this game. Finally, numerical results for the IEEE 33-bus distribution power system illustrate the effectiveness of the new framework for TEM, increasing sellers' and buyers' profits by applying SAC with the new state-action spaces. SAC is implemented as a Multi-Agent, demonstrating that players converge to a singular or one of the multiple NEs in this game. The results demonstrate that buyers converge to their optimal policies within 80 days, while sellers achieve optimality after 150 days in the games created between all participants.</p>","PeriodicalId":2,"journal":{"name":"ACS Applied Bio Materials","volume":null,"pages":null},"PeriodicalIF":4.6000,"publicationDate":"2024-08-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/gtd2.13244","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"ACS Applied Bio Materials","FirstCategoryId":"5","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1049/gtd2.13244","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MATERIALS SCIENCE, BIOMATERIALS","Score":null,"Total":0}
引用次数: 0
Abstract
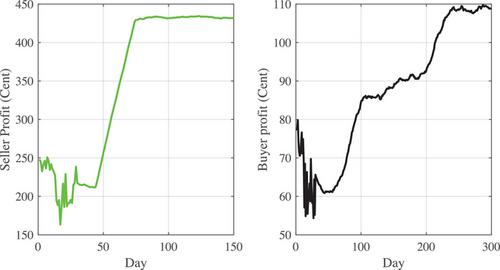
Thanks to reinforcement learning (RL), decision-making is more convenient and more economical in different situations with high uncertainty. In line with the same fact, it is proposed that prosumers can apply RL to earn more profit in the transactive energy market (TEM). In this article, an environment that represents a novel framework of TEM is designed, where all participants send their bids to this framework and receive their profit from it. Also, new state-action spaces are designed for sellers and buyers so that they can apply the Soft Actor-Critic (SAC) algorithm to converge to the best policy. A brief of this algorithm, which is for continuous state-action space, is described. First, this algorithm is implemented for a single agent (a seller and a buyer). Then we consider all players including sellers and buyers who can apply this algorithm as Multi-Agent. In this situation, there is a comprehensive game between participants that is investigated, and it is analyzed whether the players converge to the Nash equilibrium (NE) in this game. Finally, numerical results for the IEEE 33-bus distribution power system illustrate the effectiveness of the new framework for TEM, increasing sellers' and buyers' profits by applying SAC with the new state-action spaces. SAC is implemented as a Multi-Agent, demonstrating that players converge to a singular or one of the multiple NEs in this game. The results demonstrate that buyers converge to their optimal policies within 80 days, while sellers achieve optimality after 150 days in the games created between all participants.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


