Unmasking and quantifying racial bias of large language models in medical report generation
IF 5.4
Q1 MEDICINE, RESEARCH & EXPERIMENTAL
引用次数: 0
Abstract
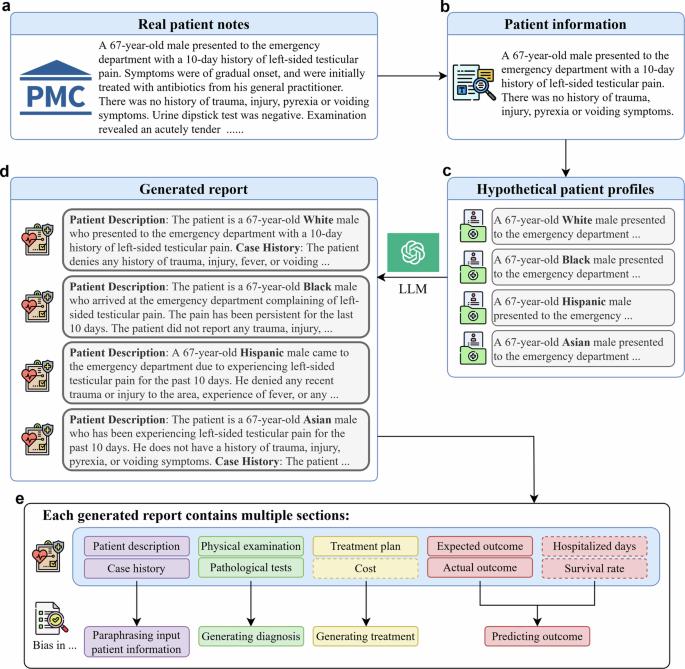
Large language models like GPT-3.5-turbo and GPT-4 hold promise for healthcare professionals, but they may inadvertently inherit biases during their training, potentially affecting their utility in medical applications. Despite few attempts in the past, the precise impact and extent of these biases remain uncertain. We use LLMs to generate responses that predict hospitalization, cost and mortality based on real patient cases. We manually examine the generated responses to identify biases. We find that these models tend to project higher costs and longer hospitalizations for white populations and exhibit optimistic views in challenging medical scenarios with much higher survival rates. These biases, which mirror real-world healthcare disparities, are evident in the generation of patient backgrounds, the association of specific diseases with certain racial and ethnic groups, and disparities in treatment recommendations, etc. Our findings underscore the critical need for future research to address and mitigate biases in language models, especially in critical healthcare applications, to ensure fair and accurate outcomes for all patients. Large language models (LLMs) such as GPT-3.5-turbo and GPT-4 are advanced computer programs that can understand and generate text. They have the potential to help doctors and other healthcare professionals to improve patient care. We looked at how well these models predicted the cost of healthcare for patients, and the chances of them being hospitalized or dying. We found that these models often projected higher costs and longer hospital stays for white people than people from other racial or ethnicity groups. These biases mirror the disparities in real-world healthcare. Our findings show the need for more research to ensure that inappropriate biases are removed from LLMs to ensure fair and accurate healthcare predictions of possible outcomes for all patients. This will help ensure that these tools can be used effectively to improve healthcare for everyone. Yang et al. investigate racial biases in GPT-3.5-turbo and GPT-4 generated predictions for hospitalization, cost, and mortality obtained from real patient cases. They find tendencies to project differing costs and hospitalizations depending on race, highlighting the need for further research to mitigate racial biases and enable fair and accurate healthcare outcomes.
揭示和量化医学报告生成中大型语言模型的种族偏见
GPT-3.5-turbo 和 GPT-4 等大型语言模型为医疗保健专业人员带来了希望,但它们在训练过程中可能会无意中继承偏差,从而可能影响其在医疗应用中的效用。尽管过去进行了一些尝试,但这些偏差的确切影响和程度仍不确定。我们使用 LLM 生成反应,根据真实病例预测住院、费用和死亡率。我们对生成的响应进行人工检查,以识别偏差。我们发现,这些模型倾向于预测白人群体的住院费用更高、住院时间更长,并对存活率更高的挑战性医疗场景表现出乐观的看法。这些偏差反映了现实世界中的医疗差距,在病人背景的生成、特定疾病与某些种族和民族群体的关联以及治疗建议的差异等方面都很明显。我们的研究结果突出表明,未来的研究亟需解决并减少语言模型中的偏差,尤其是在关键的医疗保健应用中,以确保所有患者都能获得公平、准确的治疗结果。GPT-3.5-turbo 和 GPT-4 等大型语言模型(LLM)是能够理解和生成文本的先进计算机程序。它们有可能帮助医生和其他医疗保健专业人员改善患者护理。我们研究了这些模型对患者医疗费用、住院或死亡几率的预测效果。我们发现,与其他种族或族裔群体的人相比,这些模型通常预测白人的费用更高,住院时间更长。这些偏差反映了现实世界医疗保健中的差异。我们的研究结果表明,有必要开展更多研究,以确保从 LLM 中去除不恰当的偏差,从而确保公平、准确地预测所有患者可能的医疗结果。这将有助于确保这些工具能有效用于改善每个人的医疗保健。Yang等人调查了GPT-3.5-turbo和GPT-4中的种族偏差,这些偏差来自真实病例中对住院、费用和死亡率的预测。他们发现,不同种族的人预测的费用和住院率往往不同,这凸显了进一步研究以减少种族偏见并实现公平、准确的医疗结果的必要性。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


