{"title":"Tri-AL: An open source platform for visualization and analysis of clinical trials","authors":"Pouyan Nahed , Mina Esmail Zadeh Nojoo Kambar , Kazem Taghva , Lukasz Golab","doi":"10.1016/j.is.2024.102459","DOIUrl":null,"url":null,"abstract":"<div><p>ClinicalTrials.gov hosts an online database with over 440,000 medical studies (as of 2023) evaluating drugs, supplements, medical devices, and behavioral treatments. Target users include scientists, medical researchers, pharmaceutical companies, and other public and private institutions. Although ClinicalTrials has some filtering ability, it does not provide visualization tools, reporting tools or historical data; only the most recent state of each trial is visible to users. To fill these functionality gaps, we present <em>Tri-AL</em>: an open-source data platform for clinical trial visualization, information extraction, historical analysis, and reporting. This paper describes the design and functionality of <em>Tri-AL</em>, including a programmable module to incorporate machine learning models and extract disease-specific data from unstructured trial reports, which we demonstrate using Alzheimer’s disease reporting as a case study. We also highlight the use of <em>Tri-AL</em> for trial participation analysis in terms of sex, gender, race and ethnicity. The source code is publicly available at <span><span>https://github.com/pouyan9675/Tri-AL</span><svg><path></path></svg></span>.</p></div>","PeriodicalId":50363,"journal":{"name":"Information Systems","volume":"127 ","pages":"Article 102459"},"PeriodicalIF":3.0000,"publicationDate":"2024-09-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Information Systems","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0306437924001170","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
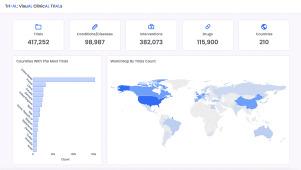
ClinicalTrials.gov hosts an online database with over 440,000 medical studies (as of 2023) evaluating drugs, supplements, medical devices, and behavioral treatments. Target users include scientists, medical researchers, pharmaceutical companies, and other public and private institutions. Although ClinicalTrials has some filtering ability, it does not provide visualization tools, reporting tools or historical data; only the most recent state of each trial is visible to users. To fill these functionality gaps, we present Tri-AL: an open-source data platform for clinical trial visualization, information extraction, historical analysis, and reporting. This paper describes the design and functionality of Tri-AL, including a programmable module to incorporate machine learning models and extract disease-specific data from unstructured trial reports, which we demonstrate using Alzheimer’s disease reporting as a case study. We also highlight the use of Tri-AL for trial participation analysis in terms of sex, gender, race and ethnicity. The source code is publicly available at https://github.com/pouyan9675/Tri-AL.
期刊介绍:
Information systems are the software and hardware systems that support data-intensive applications. The journal Information Systems publishes articles concerning the design and implementation of languages, data models, process models, algorithms, software and hardware for information systems.
Subject areas include data management issues as presented in the principal international database conferences (e.g., ACM SIGMOD/PODS, VLDB, ICDE and ICDT/EDBT) as well as data-related issues from the fields of data mining/machine learning, information retrieval coordinated with structured data, internet and cloud data management, business process management, web semantics, visual and audio information systems, scientific computing, and data science. Implementation papers having to do with massively parallel data management, fault tolerance in practice, and special purpose hardware for data-intensive systems are also welcome. Manuscripts from application domains, such as urban informatics, social and natural science, and Internet of Things, are also welcome. All papers should highlight innovative solutions to data management problems such as new data models, performance enhancements, and show how those innovations contribute to the goals of the application.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


