Yu Yan, Baradwaj Simha Sankar, Bilal Mirza, Dominic C M Ng, Alexander R Pelletier, Sarah D Huang, Wei Wang, Karol Watson, Ding Wang, Peipei Ping
{"title":"Missing Values in Longitudinal Proteome Dynamics Studies: Making a Case for Data Multiple Imputation.","authors":"Yu Yan, Baradwaj Simha Sankar, Bilal Mirza, Dominic C M Ng, Alexander R Pelletier, Sarah D Huang, Wei Wang, Karol Watson, Ding Wang, Peipei Ping","doi":"10.1021/acs.jproteome.4c00263","DOIUrl":null,"url":null,"abstract":"<p><p>Temporal proteomics data sets are often confounded by the challenges of missing values. These missing data points, in a time-series context, can lead to fluctuations in measurements or the omission of critical events, thus hindering the ability to fully comprehend the underlying biomedical processes. We introduce a Data Multiple Imputation (DMI) pipeline designed to address this challenge in temporal data set turnover rate quantifications, enabling robust downstream analysis to gain novel discoveries. To demonstrate its utility and generalizability, we applied this pipeline to two use cases: a murine cardiac temporal proteomics data set and a human plasma temporal proteomics data set, both aimed at examining protein turnover rates. This DMI pipeline significantly enhanced the detection of protein turnover rate in both data sets, and furthermore, the imputed data sets captured new representation of proteins, leading to an augmented view of biological pathways, protein complex dynamics, as well as biomarker-disease associations. Importantly, DMI exhibited superior performance in benchmark data sets compared to single imputation methods (DSI). In summary, we have demonstrated that this DMI pipeline is effective at overcoming challenges introduced by missing values in temporal proteome dynamics studies.</p>","PeriodicalId":48,"journal":{"name":"Journal of Proteome Research","volume":" ","pages":"4151-4162"},"PeriodicalIF":3.6000,"publicationDate":"2024-09-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11385379/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Proteome Research","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1021/acs.jproteome.4c00263","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/27 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
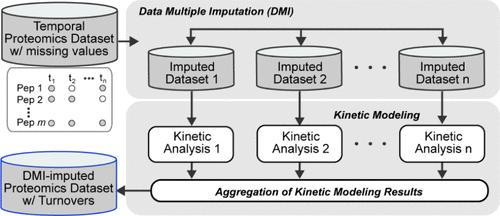
Temporal proteomics data sets are often confounded by the challenges of missing values. These missing data points, in a time-series context, can lead to fluctuations in measurements or the omission of critical events, thus hindering the ability to fully comprehend the underlying biomedical processes. We introduce a Data Multiple Imputation (DMI) pipeline designed to address this challenge in temporal data set turnover rate quantifications, enabling robust downstream analysis to gain novel discoveries. To demonstrate its utility and generalizability, we applied this pipeline to two use cases: a murine cardiac temporal proteomics data set and a human plasma temporal proteomics data set, both aimed at examining protein turnover rates. This DMI pipeline significantly enhanced the detection of protein turnover rate in both data sets, and furthermore, the imputed data sets captured new representation of proteins, leading to an augmented view of biological pathways, protein complex dynamics, as well as biomarker-disease associations. Importantly, DMI exhibited superior performance in benchmark data sets compared to single imputation methods (DSI). In summary, we have demonstrated that this DMI pipeline is effective at overcoming challenges introduced by missing values in temporal proteome dynamics studies.
期刊介绍:
Journal of Proteome Research publishes content encompassing all aspects of global protein analysis and function, including the dynamic aspects of genomics, spatio-temporal proteomics, metabonomics and metabolomics, clinical and agricultural proteomics, as well as advances in methodology including bioinformatics. The theme and emphasis is on a multidisciplinary approach to the life sciences through the synergy between the different types of "omics".

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


