Comparative Analysis of Accuracy, Readability, Sentiment, and Actionability: Artificial Intelligence Chatbots (ChatGPT and Google Gemini) versus Traditional Patient Information Leaflets for Local Anesthesia in Eye Surgery.
{"title":"Comparative Analysis of Accuracy, Readability, Sentiment, and Actionability: Artificial Intelligence Chatbots (ChatGPT and Google Gemini) versus Traditional Patient Information Leaflets for Local Anesthesia in Eye Surgery.","authors":"Prakash Gondode, Sakshi Duggal, Neha Garg, Pooja Lohakare, Jubin Jakhar, Swati Bharti, Shraddha Dewangan","doi":"10.22599/bioj.377","DOIUrl":null,"url":null,"abstract":"<p><strong>Background and aim: </strong>Eye surgeries often evoke strong negative emotions in patients, including fear and anxiety. Patient education material plays a crucial role in informing and empowering individuals. Traditional sources of medical information may not effectively address individual patient concerns or cater to varying levels of understanding. This study aims to conduct a comparative analysis of the accuracy, completeness, readability, tone, and understandability of patient education material generated by AI chatbots versus traditional Patient Information Leaflets (PILs), focusing on local anesthesia in eye surgery.</p><p><strong>Methods: </strong>Expert reviewers evaluated responses generated by AI chatbots (ChatGPT and Google Gemini) and a traditional PIL (Royal College of Anaesthetists' PIL) based on accuracy, completeness, readability, sentiment, and understandability. Statistical analyses, including ANOVA and Tukey HSD tests, were conducted to compare the performance of the sources.</p><p><strong>Results: </strong>Readability analysis showed variations in complexity among the sources, with AI chatbots offering simplified language and PILs maintaining better overall readability and accessibility. Sentiment analysis revealed differences in emotional tone, with Google Gemini exhibiting the most positive sentiment. AI chatbots demonstrated superior understandability and actionability, while PILs excelled in completeness. Overall, ChatGPT showed slightly higher accuracy (scores expressed as mean ± standard deviation) (4.71 ± 0.5 vs 4.61 ± 0.62) and completeness (4.55 ± 0.58 vs 4.47 ± 0.58) compared to Google Gemini, but PILs performed best (4.84 ± 0.37 vs 4.88 ± 0.33) in terms of both accuracy and completeness (p-value for completeness <0.05).</p><p><strong>Conclusion: </strong>AI chatbots show promise as innovative tools for patient education, complementing traditional PILs. By leveraging the strengths of both AI-driven technologies and human expertise, healthcare providers can enhance patient education and empower individuals to make informed decisions about their health and medical care.</p>","PeriodicalId":36083,"journal":{"name":"British and Irish Orthoptic Journal","volume":"20 1","pages":"183-192"},"PeriodicalIF":0.0000,"publicationDate":"2024-08-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11342839/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"British and Irish Orthoptic Journal","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.22599/bioj.377","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"Medicine","Score":null,"Total":0}
引用次数: 0
Abstract
Background and aim: Eye surgeries often evoke strong negative emotions in patients, including fear and anxiety. Patient education material plays a crucial role in informing and empowering individuals. Traditional sources of medical information may not effectively address individual patient concerns or cater to varying levels of understanding. This study aims to conduct a comparative analysis of the accuracy, completeness, readability, tone, and understandability of patient education material generated by AI chatbots versus traditional Patient Information Leaflets (PILs), focusing on local anesthesia in eye surgery.
Methods: Expert reviewers evaluated responses generated by AI chatbots (ChatGPT and Google Gemini) and a traditional PIL (Royal College of Anaesthetists' PIL) based on accuracy, completeness, readability, sentiment, and understandability. Statistical analyses, including ANOVA and Tukey HSD tests, were conducted to compare the performance of the sources.
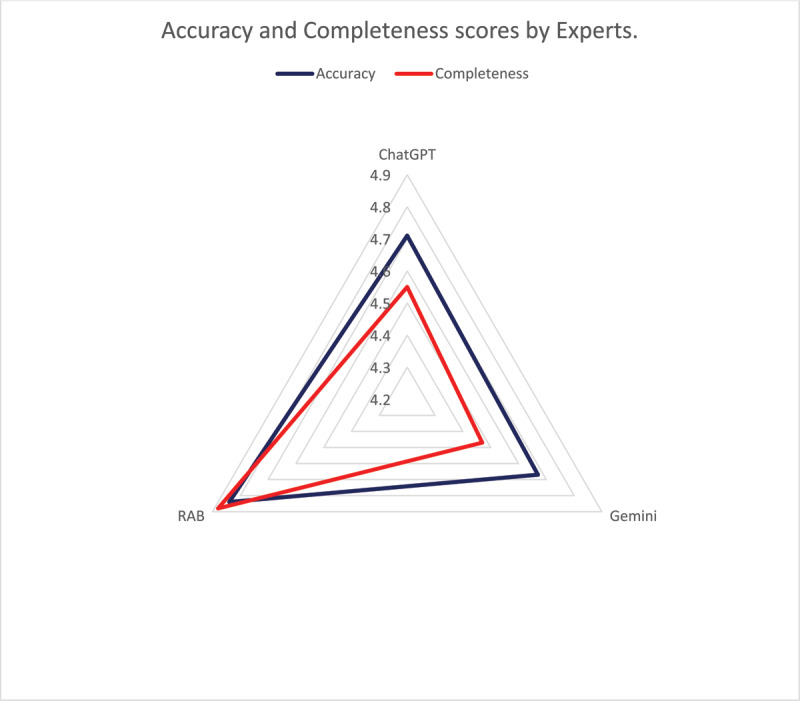
Results: Readability analysis showed variations in complexity among the sources, with AI chatbots offering simplified language and PILs maintaining better overall readability and accessibility. Sentiment analysis revealed differences in emotional tone, with Google Gemini exhibiting the most positive sentiment. AI chatbots demonstrated superior understandability and actionability, while PILs excelled in completeness. Overall, ChatGPT showed slightly higher accuracy (scores expressed as mean ± standard deviation) (4.71 ± 0.5 vs 4.61 ± 0.62) and completeness (4.55 ± 0.58 vs 4.47 ± 0.58) compared to Google Gemini, but PILs performed best (4.84 ± 0.37 vs 4.88 ± 0.33) in terms of both accuracy and completeness (p-value for completeness <0.05).
Conclusion: AI chatbots show promise as innovative tools for patient education, complementing traditional PILs. By leveraging the strengths of both AI-driven technologies and human expertise, healthcare providers can enhance patient education and empower individuals to make informed decisions about their health and medical care.
准确性、可读性、情感和可操作性的比较分析:人工智能聊天机器人(ChatGPT 和 Google Gemini)与传统眼科手术局部麻醉患者信息手册的比较分析。
背景和目的:眼科手术通常会唤起患者强烈的负面情绪,包括恐惧和焦虑。患者教育材料在提供信息和增强个人能力方面起着至关重要的作用。传统的医疗信息来源可能无法有效解决患者的个人顾虑或满足不同程度的理解需求。本研究旨在对人工智能聊天机器人生成的患者教育材料与传统患者信息单(PIL)的准确性、完整性、可读性、语气和可理解性进行比较分析,重点关注眼科手术中的局部麻醉:专家评审员根据准确性、完整性、可读性、情感和可理解性对人工智能聊天机器人(ChatGPT 和 Google Gemini)和传统 PIL(英国皇家麻醉师学院 PIL)生成的回复进行了评估。我们进行了统计分析,包括方差分析和 Tukey HSD 检验,以比较这些信息源的性能:结果:可读性分析表明,不同信息源的复杂性存在差异,人工智能聊天机器人提供了简化的语言,而 PIL 则保持了更好的整体可读性和可访问性。情感分析显示了情感基调的差异,谷歌双子座表现出最积极的情感。人工智能聊天机器人在可理解性和可操作性方面表现出色,而 PIL 则在完整性方面更胜一筹。总体而言,与谷歌双子座相比,ChatGPT 的准确性(以平均值±标准差表示的分数)(4.71±0.5 vs 4.61±0.62)和完整性(4.55±0.58 vs 4.47±0.58)略高,但 PIL 在准确性和完整性方面表现最佳(4.84±0.37 vs 4.88±0.33)(完整性的 p 值为结论):人工智能聊天机器人有望成为患者教育的创新工具,补充传统的 PIL。通过利用人工智能驱动的技术和人类专业知识的优势,医疗保健提供商可以加强患者教育,使个人有能力就其健康和医疗保健做出明智的决定。

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


