Simeng Ma, Ruiling Li, Qian Gong, Honggang Lv, Zipeng Deng, Beibei Wang, Lihua Yao, Lijun Kang, Dan Xiang, Jun Yang, Zhongchun Liu
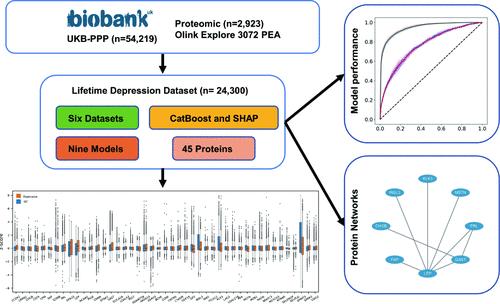
{"title":"Using Data-Driven Algorithms with Large-Scale Plasma Proteomic Data to Discover Novel Biomarkers for Diagnosing Depression.","authors":"Simeng Ma, Ruiling Li, Qian Gong, Honggang Lv, Zipeng Deng, Beibei Wang, Lihua Yao, Lijun Kang, Dan Xiang, Jun Yang, Zhongchun Liu","doi":"10.1021/acs.jproteome.4c00389","DOIUrl":null,"url":null,"abstract":"<p><p>Given recent technological advances in proteomics, it is now possible to quantify plasma proteomes in large cohorts of patients to screen for biomarkers and to guide the early diagnosis and treatment of depression. Here we used CatBoost machine learning to model and discover biomarkers of depression in UK Biobank data sets (depression <i>n</i> = 4,479, healthy control <i>n</i> = 19,821). CatBoost was employed for model construction, with Shapley Additive Explanations (SHAP) being utilized to interpret the resulting model. Model performance was corroborated through 5-fold cross-validation, and its diagnostic efficacy was evaluated based on the area under the receiver operating characteristic (AUC) curve. A total of 45 depression-related proteins were screened based on the top 20 important features output by the CatBoost model in six data sets. Of the nine diagnostic models for depression, the performance of the traditional risk factor model was improved after the addition of proteomic data, with the best model having an average AUC of 0.764 in the test sets. KEGG pathway analysis of 45 screened proteins showed that the most significant pathway involved was the cytokine-cytokine receptor interaction. It is feasible to explore diagnostic biomarkers of depression using data-driven machine learning methods and large-scale data sets, although the results require validation.</p>","PeriodicalId":48,"journal":{"name":"Journal of Proteome Research","volume":null,"pages":null},"PeriodicalIF":3.8000,"publicationDate":"2024-09-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Proteome Research","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1021/acs.jproteome.4c00389","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/16 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
Given recent technological advances in proteomics, it is now possible to quantify plasma proteomes in large cohorts of patients to screen for biomarkers and to guide the early diagnosis and treatment of depression. Here we used CatBoost machine learning to model and discover biomarkers of depression in UK Biobank data sets (depression n = 4,479, healthy control n = 19,821). CatBoost was employed for model construction, with Shapley Additive Explanations (SHAP) being utilized to interpret the resulting model. Model performance was corroborated through 5-fold cross-validation, and its diagnostic efficacy was evaluated based on the area under the receiver operating characteristic (AUC) curve. A total of 45 depression-related proteins were screened based on the top 20 important features output by the CatBoost model in six data sets. Of the nine diagnostic models for depression, the performance of the traditional risk factor model was improved after the addition of proteomic data, with the best model having an average AUC of 0.764 in the test sets. KEGG pathway analysis of 45 screened proteins showed that the most significant pathway involved was the cytokine-cytokine receptor interaction. It is feasible to explore diagnostic biomarkers of depression using data-driven machine learning methods and large-scale data sets, although the results require validation.
期刊介绍:
Journal of Proteome Research publishes content encompassing all aspects of global protein analysis and function, including the dynamic aspects of genomics, spatio-temporal proteomics, metabonomics and metabolomics, clinical and agricultural proteomics, as well as advances in methodology including bioinformatics. The theme and emphasis is on a multidisciplinary approach to the life sciences through the synergy between the different types of "omics".

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


