Effects of tuning decision trees in random forest regression on predicting porosity of a hydrocarbon reservoir. A case study: volve oil field, north sea
Kushan Sandunil, Ziad Bennour, Hisham Ben Mahmud and Ausama Giwelli
{"title":"Effects of tuning decision trees in random forest regression on predicting porosity of a hydrocarbon reservoir. A case study: volve oil field, north sea","authors":"Kushan Sandunil, Ziad Bennour, Hisham Ben Mahmud and Ausama Giwelli","doi":"10.1039/D4YA00313F","DOIUrl":null,"url":null,"abstract":"<p >Machine learning (ML) has emerged as a powerful tool in petroleum engineering for automatically interpreting well logs and characterizing reservoir properties such as porosity. As a result, researchers are trying to enhance the performance of ML models further to widen their applicability in the real world. Random forest regression (RFR) is one such widely used ML technique that was developed by combining multiple decision trees. To improve its performance, one of its hyperparameters, the number of trees in the forest (<em>n_estimators</em>), is tuned during model optimization. However, the existing literature lacks in-depth studies on the influence of <em>n_estimators</em> on the RFR model when used for predicting porosity, given that <em>n_estimators</em> is one of the most influential hyperparameters that can be tuned to optimize the RFR algorithm. In this study, the effects of <em>n_estimators</em> on the RFR model in porosity prediction were investigated. Furthermore, <em>n_estimators</em>’ interactions with two other key hyperparameters, namely the number of features considered for the best split (<em>max_features</em>) and the minimum number of samples required to be at a leaf node (<em>min_samples_leaf</em>) were explored. The RFR models were developed using 4 input features, namely, resistivity log (RES), neutron porosity log (NPHI), gamma ray log (GR), and the corresponding depths obtained from the Volve oil field in the North Sea, and calculated porosity was used as the target data. The methodology consisted of 4 approaches. In the first approach, only <em>n_estimators</em> were changed; in the second approach, <em>n_estimators</em> were changed along with <em>max_features</em>; in the third approach, <em>n_estimators</em> were changed along with <em>min_samples_leaf</em>; and in the final approach, all three hyperparameters were tuned. Altogether 24 RFR models were developed, and models were evaluated using adjusted <em>R</em><small><sup>2</sup></small> (adj. <em>R</em><small><sup>2</sup></small>), root mean squared error (RMSE), and their computational times. The obtained results showed that the highest performance with an adj. <em>R</em><small><sup>2</sup></small> value of 0.8505 was achieved when <em>n_estimators</em> was 81, <em>max_features</em> was 2 and <em>min_samples_leaf</em> was 1. In approach 2, when <em>n_estimators’</em> upper limit was increased from 10 to 100, there was a test model performance growth of more than 1.60%, whereas increasing <em>n_estimators’</em> upper limit from 100 to 1000 showed a performance drop of around 0.4%. Models developed by tuning <em>n_estimators</em> from 1 to 100 in intervals of 10 had healthy test model adj. <em>R</em><small><sup>2</sup></small> values and lower computational times, making them the best <em>n_estimators’</em> range and interval when both performances and computational times were taken into consideration to predict the porosity of the Volve oil field in the North Sea. Thus, it was concluded that by tuning only <em>n_estimators</em> and <em>max_features</em>, the performance of RFR models can be increased significantly.</p>","PeriodicalId":72913,"journal":{"name":"Energy advances","volume":" 9","pages":" 2335-2347"},"PeriodicalIF":3.2000,"publicationDate":"2024-08-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://pubs.rsc.org/en/content/articlepdf/2024/ya/d4ya00313f?page=search","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Energy advances","FirstCategoryId":"1085","ListUrlMain":"https://pubs.rsc.org/en/content/articlelanding/2024/ya/d4ya00313f","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"CHEMISTRY, PHYSICAL","Score":null,"Total":0}
引用次数: 0
Abstract
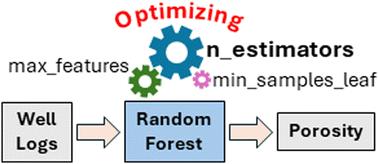
Machine learning (ML) has emerged as a powerful tool in petroleum engineering for automatically interpreting well logs and characterizing reservoir properties such as porosity. As a result, researchers are trying to enhance the performance of ML models further to widen their applicability in the real world. Random forest regression (RFR) is one such widely used ML technique that was developed by combining multiple decision trees. To improve its performance, one of its hyperparameters, the number of trees in the forest (n_estimators), is tuned during model optimization. However, the existing literature lacks in-depth studies on the influence of n_estimators on the RFR model when used for predicting porosity, given that n_estimators is one of the most influential hyperparameters that can be tuned to optimize the RFR algorithm. In this study, the effects of n_estimators on the RFR model in porosity prediction were investigated. Furthermore, n_estimators’ interactions with two other key hyperparameters, namely the number of features considered for the best split (max_features) and the minimum number of samples required to be at a leaf node (min_samples_leaf) were explored. The RFR models were developed using 4 input features, namely, resistivity log (RES), neutron porosity log (NPHI), gamma ray log (GR), and the corresponding depths obtained from the Volve oil field in the North Sea, and calculated porosity was used as the target data. The methodology consisted of 4 approaches. In the first approach, only n_estimators were changed; in the second approach, n_estimators were changed along with max_features; in the third approach, n_estimators were changed along with min_samples_leaf; and in the final approach, all three hyperparameters were tuned. Altogether 24 RFR models were developed, and models were evaluated using adjusted R2 (adj. R2), root mean squared error (RMSE), and their computational times. The obtained results showed that the highest performance with an adj. R2 value of 0.8505 was achieved when n_estimators was 81, max_features was 2 and min_samples_leaf was 1. In approach 2, when n_estimators’ upper limit was increased from 10 to 100, there was a test model performance growth of more than 1.60%, whereas increasing n_estimators’ upper limit from 100 to 1000 showed a performance drop of around 0.4%. Models developed by tuning n_estimators from 1 to 100 in intervals of 10 had healthy test model adj. R2 values and lower computational times, making them the best n_estimators’ range and interval when both performances and computational times were taken into consideration to predict the porosity of the Volve oil field in the North Sea. Thus, it was concluded that by tuning only n_estimators and max_features, the performance of RFR models can be increased significantly.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


