Yinglin Zheng , Ting Zhang , Jianmin Bao , Dong Chen , Ming Zeng
{"title":"High-fidelity instructional fashion image editing","authors":"Yinglin Zheng , Ting Zhang , Jianmin Bao , Dong Chen , Ming Zeng","doi":"10.1016/j.gmod.2024.101223","DOIUrl":null,"url":null,"abstract":"<div><p>Instructional image editing has received a significant surge of attention recently. In this work, we are interested in the challenging problem of instructional image editing within the particular fashion realm, a domain with significant potential demand in both commercial and personal contexts. This specific domain presents heightened challenges owing to the stringent quality requirements. It necessitates not only the creation of vivid details in alignment with instructions, but also the preservation of precise attributes unrelated to the text guidance. Naive extensions of existing image editing methods produce noticeable artifacts. In order to achieve high-fidelity fashion editing, we propose a novel framework, leveraging the generative prior of a pre-trained human generator and performing edit in the latent space. In addition, we introduce a novel CLIP-based loss to better align the generated target with the instruction. Extensive experiments demonstrate that our approach outperforms prior works including GAN-based editing as well as diffusion-based editing by a large margin, showing impressive visual quality.</p></div>","PeriodicalId":55083,"journal":{"name":"Graphical Models","volume":"135 ","pages":"Article 101223"},"PeriodicalIF":2.2000,"publicationDate":"2024-07-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S1524070324000110/pdfft?md5=480bdc352d9fc3901d6a01e1e2794553&pid=1-s2.0-S1524070324000110-main.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Graphical Models","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1524070324000110","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
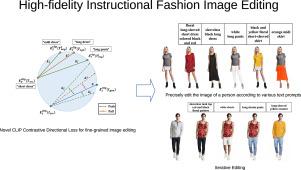
Instructional image editing has received a significant surge of attention recently. In this work, we are interested in the challenging problem of instructional image editing within the particular fashion realm, a domain with significant potential demand in both commercial and personal contexts. This specific domain presents heightened challenges owing to the stringent quality requirements. It necessitates not only the creation of vivid details in alignment with instructions, but also the preservation of precise attributes unrelated to the text guidance. Naive extensions of existing image editing methods produce noticeable artifacts. In order to achieve high-fidelity fashion editing, we propose a novel framework, leveraging the generative prior of a pre-trained human generator and performing edit in the latent space. In addition, we introduce a novel CLIP-based loss to better align the generated target with the instruction. Extensive experiments demonstrate that our approach outperforms prior works including GAN-based editing as well as diffusion-based editing by a large margin, showing impressive visual quality.
最近,教学图像编辑受到了广泛关注。在这项工作中,我们关注的是在特定时尚领域中进行教学图像编辑这一具有挑战性的问题,该领域在商业和个人方面都有巨大的潜在需求。由于对质量的严格要求,这一特定领域面临着更大的挑战。它不仅需要根据说明创建生动的细节,还需要保留与文本指导无关的精确属性。现有图像编辑方法的简单扩展会产生明显的人工痕迹。为了实现高保真时装编辑,我们提出了一个新颖的框架,利用预先训练好的人类生成器的生成先验,在潜空间中进行编辑。此外,我们还引入了一种新颖的基于 CLIP 的损失,使生成的目标与指令更好地保持一致。广泛的实验证明,我们的方法远远优于之前的工作,包括基于 GAN 的编辑和基于扩散的编辑,显示出令人印象深刻的视觉质量。
期刊介绍:
Graphical Models is recognized internationally as a highly rated, top tier journal and is focused on the creation, geometric processing, animation, and visualization of graphical models and on their applications in engineering, science, culture, and entertainment. GMOD provides its readers with thoroughly reviewed and carefully selected papers that disseminate exciting innovations, that teach rigorous theoretical foundations, that propose robust and efficient solutions, or that describe ambitious systems or applications in a variety of topics.
We invite papers in five categories: research (contributions of novel theoretical or practical approaches or solutions), survey (opinionated views of the state-of-the-art and challenges in a specific topic), system (the architecture and implementation details of an innovative architecture for a complete system that supports model/animation design, acquisition, analysis, visualization?), application (description of a novel application of know techniques and evaluation of its impact), or lecture (an elegant and inspiring perspective on previously published results that clarifies them and teaches them in a new way).
GMOD offers its authors an accelerated review, feedback from experts in the field, immediate online publication of accepted papers, no restriction on color and length (when justified by the content) in the online version, and a broad promotion of published papers. A prestigious group of editors selected from among the premier international researchers in their fields oversees the review process.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


