{"title":"Cooperative Path Planning for Multiplayer Reach-Avoid Games under Imperfect Observation Information","authors":"Hongwei Fang, Yue Chen, Peng Yi","doi":"10.1002/aisy.202300794","DOIUrl":null,"url":null,"abstract":"<p>This article investigates a reach-avoid game and proposes a cooperative path planning algorithm for a target–pursuers (TP) coalition to capture an evader. In the game, the target aims to bait and escape from the evader, and the pursuer aims to capture the evader. Due to imperfect observations, the TP coalition has uncertain information of the evader's state, while the evader is assumed to have perfect observation. The game model is constructed by formulating the optimization problems for each player in a receding horizon fashion. Then, to counter the evader effectively, the TP coalition constructs a virtual evader using the belief information from a Kalman filter. And a chance constraint optimization problem is constructed to predict the virtual evader's trajectory under uncertainties. The TP coalition can capture the actual evader by generating a robust counter-strategy against the virtual evader with a chance constraint feasible set. Next, to compute the Nash equilibrium of the TP coalition's subjective game, an iterative algorithm is designed that combines the iterative best response and the distributed alternating direction method of multiplier algorithms. Finally, the effectiveness of the algorithm is validated through simulations and experiments.</p>","PeriodicalId":93858,"journal":{"name":"Advanced intelligent systems (Weinheim an der Bergstrasse, Germany)","volume":"6 9","pages":""},"PeriodicalIF":6.8000,"publicationDate":"2024-07-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/aisy.202300794","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advanced intelligent systems (Weinheim an der Bergstrasse, Germany)","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/aisy.202300794","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"AUTOMATION & CONTROL SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
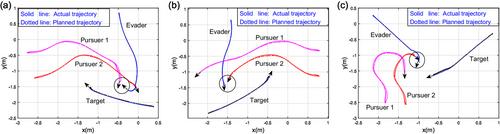
This article investigates a reach-avoid game and proposes a cooperative path planning algorithm for a target–pursuers (TP) coalition to capture an evader. In the game, the target aims to bait and escape from the evader, and the pursuer aims to capture the evader. Due to imperfect observations, the TP coalition has uncertain information of the evader's state, while the evader is assumed to have perfect observation. The game model is constructed by formulating the optimization problems for each player in a receding horizon fashion. Then, to counter the evader effectively, the TP coalition constructs a virtual evader using the belief information from a Kalman filter. And a chance constraint optimization problem is constructed to predict the virtual evader's trajectory under uncertainties. The TP coalition can capture the actual evader by generating a robust counter-strategy against the virtual evader with a chance constraint feasible set. Next, to compute the Nash equilibrium of the TP coalition's subjective game, an iterative algorithm is designed that combines the iterative best response and the distributed alternating direction method of multiplier algorithms. Finally, the effectiveness of the algorithm is validated through simulations and experiments.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


