{"title":"LDTR: Transformer-based lane detection with anchor-chain representation","authors":"Zhongyu Yang, Chen Shen, Wei Shao, Tengfei Xing, Runbo Hu, Pengfei Xu, Hua Chai, Ruini Xue","doi":"10.1007/s41095-024-0421-5","DOIUrl":null,"url":null,"abstract":"<p>Despite recent advances in lane detection methods, scenarios with limited- or no-visual-clue of lanes due to factors such as lighting conditions and occlusion remain challenging and crucial for automated driving. Moreover, current lane representations require complex post-processing and struggle with specific instances. Inspired by the DETR architecture, we propose LDTR, a transformer-based model to address these issues. Lanes are modeled with a novel anchor-chain, regarding a lane as a whole from the beginning, which enables LDTR to handle special lanes inherently. To enhance lane instance perception, LDTR incorporates a novel multi-referenced deformable attention module to distribute attention around the object. Additionally, LDTR incorporates two line IoU algorithms to improve convergence efficiency and employs a Gaussian heatmap auxiliary branch to enhance model representation capability during training. To evaluate lane detection models, we rely on Fréchet distance, parameterized Fl-score, and additional synthetic metrics. Experimental results demonstrate that LDTR achieves state-of-the-art performance on well-known datasets.</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"32 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-07-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-024-0421-5","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
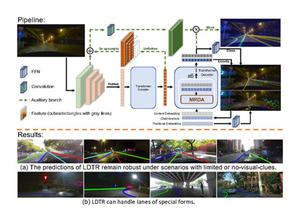
Despite recent advances in lane detection methods, scenarios with limited- or no-visual-clue of lanes due to factors such as lighting conditions and occlusion remain challenging and crucial for automated driving. Moreover, current lane representations require complex post-processing and struggle with specific instances. Inspired by the DETR architecture, we propose LDTR, a transformer-based model to address these issues. Lanes are modeled with a novel anchor-chain, regarding a lane as a whole from the beginning, which enables LDTR to handle special lanes inherently. To enhance lane instance perception, LDTR incorporates a novel multi-referenced deformable attention module to distribute attention around the object. Additionally, LDTR incorporates two line IoU algorithms to improve convergence efficiency and employs a Gaussian heatmap auxiliary branch to enhance model representation capability during training. To evaluate lane detection models, we rely on Fréchet distance, parameterized Fl-score, and additional synthetic metrics. Experimental results demonstrate that LDTR achieves state-of-the-art performance on well-known datasets.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


