Jasper M Morrow, Sachit Shah, Lara Cristiano, Matthew R B Evans, Carolynne M Doherty, Talal Alnaemi, Abeer Saab, Ahmed Emira, Uros Klickovic, Ahmed Hammam, Afnan Altuwaijri, Stephen Wastling, Mary M Reilly, Michael G Hanna, Tarek A Yousry, John S Thornton
{"title":"Development of an initial training and evaluation programme for manual lower limb muscle MRI segmentation.","authors":"Jasper M Morrow, Sachit Shah, Lara Cristiano, Matthew R B Evans, Carolynne M Doherty, Talal Alnaemi, Abeer Saab, Ahmed Emira, Uros Klickovic, Ahmed Hammam, Afnan Altuwaijri, Stephen Wastling, Mary M Reilly, Michael G Hanna, Tarek A Yousry, John S Thornton","doi":"10.1186/s41747-024-00475-9","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Magnetic resonance imaging (MRI) quantification of intramuscular fat accumulation is a responsive biomarker in neuromuscular diseases. Despite emergence of automated methods, manual muscle segmentation remains an essential foundation. We aimed to develop a training programme for new observers to demonstrate competence in lower limb muscle segmentation and establish reliability benchmarks for future human observers and machine learning segmentation packages.</p><p><strong>Methods: </strong>The learning phase of the training programme comprised a training manual, direct instruction, and eight lower limb MRI scans with reference standard large and small regions of interest (ROIs). The assessment phase used test-retest scans from two patients and two healthy controls. Interscan and interobserver reliability metrics were calculated to identify underperforming outliers and to determine competency benchmarks.</p><p><strong>Results: </strong>Three experienced observers undertook the assessment phase, whilst eight new observers completed the full training programme. Two of the new observers were identified as underperforming outliers, relating to variation in size or consistency of segmentations; six had interscan and interobserver reliability equivalent to those of experienced observers. The calculated benchmark for the Sørensen-Dice similarity coefficient between observers was greater than 0.87 and 0.92 for individual thigh and calf muscles, respectively. Interscan and interobserver reliability were significantly higher for large than small ROIs (all p < 0.001).</p><p><strong>Conclusions: </strong>We developed, implemented, and analysed the first formal training programme for manual lower limb muscle segmentation. Large ROI showed superior reliability to small ROI for fat fraction assessment.</p><p><strong>Relevance statement: </strong>Observers competent in lower limb muscle segmentation are critical to application of quantitative muscle MRI biomarkers in neuromuscular diseases. This study has established competency benchmarks for future human observers or automated segmentation methods.</p><p><strong>Key points: </strong>• Observers competent in muscle segmentation are critical for quantitative muscle MRI biomarkers. • A training programme for muscle segmentation was undertaken by eight new observers. • We established competency benchmarks for future human observers or automated segmentation methods.</p>","PeriodicalId":36926,"journal":{"name":"European Radiology Experimental","volume":"8 1","pages":"85"},"PeriodicalIF":3.7000,"publicationDate":"2024-07-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11282017/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"European Radiology Experimental","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s41747-024-00475-9","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Magnetic resonance imaging (MRI) quantification of intramuscular fat accumulation is a responsive biomarker in neuromuscular diseases. Despite emergence of automated methods, manual muscle segmentation remains an essential foundation. We aimed to develop a training programme for new observers to demonstrate competence in lower limb muscle segmentation and establish reliability benchmarks for future human observers and machine learning segmentation packages.
Methods: The learning phase of the training programme comprised a training manual, direct instruction, and eight lower limb MRI scans with reference standard large and small regions of interest (ROIs). The assessment phase used test-retest scans from two patients and two healthy controls. Interscan and interobserver reliability metrics were calculated to identify underperforming outliers and to determine competency benchmarks.
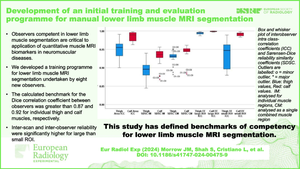
Results: Three experienced observers undertook the assessment phase, whilst eight new observers completed the full training programme. Two of the new observers were identified as underperforming outliers, relating to variation in size or consistency of segmentations; six had interscan and interobserver reliability equivalent to those of experienced observers. The calculated benchmark for the Sørensen-Dice similarity coefficient between observers was greater than 0.87 and 0.92 for individual thigh and calf muscles, respectively. Interscan and interobserver reliability were significantly higher for large than small ROIs (all p < 0.001).
Conclusions: We developed, implemented, and analysed the first formal training programme for manual lower limb muscle segmentation. Large ROI showed superior reliability to small ROI for fat fraction assessment.
Relevance statement: Observers competent in lower limb muscle segmentation are critical to application of quantitative muscle MRI biomarkers in neuromuscular diseases. This study has established competency benchmarks for future human observers or automated segmentation methods.
Key points: • Observers competent in muscle segmentation are critical for quantitative muscle MRI biomarkers. • A training programme for muscle segmentation was undertaken by eight new observers. • We established competency benchmarks for future human observers or automated segmentation methods.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


