{"title":"Identifying Depression Through Machine Learning Analysis of Omics Data: Scoping Review.","authors":"Brittany Taylor, Mollie Hobensack, Stephanie Niño de Rivera, Yihong Zhao, Ruth Masterson Creber, Kenrick Cato","doi":"10.2196/54810","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Depression is one of the most common mental disorders that affects >300 million people worldwide. There is a shortage of providers trained in the provision of mental health care, and the nursing workforce is essential in filling this gap. The diagnosis of depression relies heavily on self-reported symptoms and clinical interviews, which are subject to implicit biases. The omics methods, including genomics, transcriptomics, epigenomics, and microbiomics, are novel methods for identifying the biological underpinnings of depression. Machine learning is used to analyze genomic data that includes large, heterogeneous, and multidimensional data sets.</p><p><strong>Objective: </strong>This scoping review aims to review the existing literature on machine learning methods for omics data analysis to identify individuals with depression, with the goal of providing insight into alternative objective and driven insights into the diagnostic process for depression.</p><p><strong>Methods: </strong>This scoping review was reported following the PRISMA-ScR (Preferred Reporting Items for Systematic Reviews and Meta-Analyses Extension for Scoping Reviews) guidelines. Searches were conducted in 3 databases to identify relevant publications. A total of 3 independent researchers performed screening, and discrepancies were resolved by consensus. Critical appraisal was performed using the Joanna Briggs Institute Critical Appraisal Checklist for Analytical Cross-Sectional Studies.</p><p><strong>Results: </strong>The screening process identified 15 relevant papers. The omics methods included genomics, transcriptomics, epigenomics, multiomics, and microbiomics, and machine learning methods included random forest, support vector machine, k-nearest neighbor, and artificial neural network.</p><p><strong>Conclusions: </strong>The findings of this scoping review indicate that the omics methods had similar performance in identifying omics variants associated with depression. All machine learning methods performed well based on their performance metrics. When variants in omics data are associated with an increased risk of depression, the important next step is for clinicians, especially nurses, to assess individuals for symptoms of depression and provide a diagnosis and any necessary treatment.</p>","PeriodicalId":73556,"journal":{"name":"JMIR nursing","volume":"7 ","pages":"e54810"},"PeriodicalIF":4.0000,"publicationDate":"2024-07-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11297379/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR nursing","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/54810","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Depression is one of the most common mental disorders that affects >300 million people worldwide. There is a shortage of providers trained in the provision of mental health care, and the nursing workforce is essential in filling this gap. The diagnosis of depression relies heavily on self-reported symptoms and clinical interviews, which are subject to implicit biases. The omics methods, including genomics, transcriptomics, epigenomics, and microbiomics, are novel methods for identifying the biological underpinnings of depression. Machine learning is used to analyze genomic data that includes large, heterogeneous, and multidimensional data sets.
Objective: This scoping review aims to review the existing literature on machine learning methods for omics data analysis to identify individuals with depression, with the goal of providing insight into alternative objective and driven insights into the diagnostic process for depression.
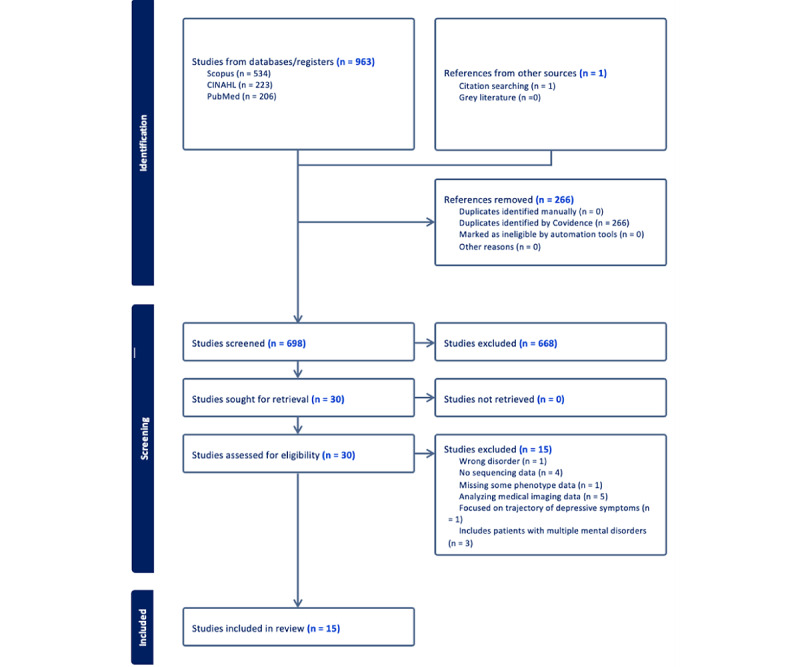
Methods: This scoping review was reported following the PRISMA-ScR (Preferred Reporting Items for Systematic Reviews and Meta-Analyses Extension for Scoping Reviews) guidelines. Searches were conducted in 3 databases to identify relevant publications. A total of 3 independent researchers performed screening, and discrepancies were resolved by consensus. Critical appraisal was performed using the Joanna Briggs Institute Critical Appraisal Checklist for Analytical Cross-Sectional Studies.
Results: The screening process identified 15 relevant papers. The omics methods included genomics, transcriptomics, epigenomics, multiomics, and microbiomics, and machine learning methods included random forest, support vector machine, k-nearest neighbor, and artificial neural network.
Conclusions: The findings of this scoping review indicate that the omics methods had similar performance in identifying omics variants associated with depression. All machine learning methods performed well based on their performance metrics. When variants in omics data are associated with an increased risk of depression, the important next step is for clinicians, especially nurses, to assess individuals for symptoms of depression and provide a diagnosis and any necessary treatment.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


