{"title":"Continual few-shot patch-based learning for anime-style colorization","authors":"Akinobu Maejima, Seitaro Shinagawa, Hiroyuki Kubo, Takuya Funatomi, Tatsuo Yotsukura, Satoshi Nakamura, Yasuhiro Mukaigawa","doi":"10.1007/s41095-024-0414-4","DOIUrl":null,"url":null,"abstract":"<p>The automatic colorization of anime line drawings is a challenging problem in production pipelines. Recent advances in deep neural networks have addressed this problem; however, collectingmany images of colorization targets in novel anime work before the colorization process starts leads to chicken-and-egg problems and has become an obstacle to using them in production pipelines. To overcome this obstacle, we propose a new patch-based learning method for few-shot anime-style colorization. The learning method adopts an efficient patch sampling technique with position embedding according to the characteristics of anime line drawings. We also present a continuous learning strategy that continuously updates our colorization model using new samples colorized by human artists. The advantage of our method is that it can learn our colorization model from scratch or pre-trained weights using only a few pre- and post-colorized line drawings that are created by artists in their usual colorization work. Therefore, our method can be easily incorporated within existing production pipelines. We quantitatively demonstrate that our colorizationmethod outperforms state-of-the-art methods.</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"46 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-07-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-024-0414-4","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
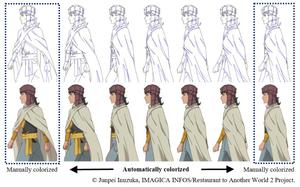
The automatic colorization of anime line drawings is a challenging problem in production pipelines. Recent advances in deep neural networks have addressed this problem; however, collectingmany images of colorization targets in novel anime work before the colorization process starts leads to chicken-and-egg problems and has become an obstacle to using them in production pipelines. To overcome this obstacle, we propose a new patch-based learning method for few-shot anime-style colorization. The learning method adopts an efficient patch sampling technique with position embedding according to the characteristics of anime line drawings. We also present a continuous learning strategy that continuously updates our colorization model using new samples colorized by human artists. The advantage of our method is that it can learn our colorization model from scratch or pre-trained weights using only a few pre- and post-colorized line drawings that are created by artists in their usual colorization work. Therefore, our method can be easily incorporated within existing production pipelines. We quantitatively demonstrate that our colorizationmethod outperforms state-of-the-art methods.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


